
rubus0304 님의 블로그
[통계학 기초] 4,5,6강 본문
https://teamsparta.notion.site/Regression-369527fd824146ba9a5dd98041e242f1
[스파르타코딩클럽] 회귀(Regression) | Notion
[수업 목표]
teamsparta.notion.site
연습문제
✔️ 이번에 배운 내용을 다시 정리하기 위해 연습문제를 풀어봅시다! (정답 해설을 보지 않고 풀어보세요!)
- 단순선형회귀 모델에서 독립변수 X와 종속변수 Y의 관계를 설명하는 회귀 직선의 방정식은 무엇인가요?

- 정답 및 해설
- 정답은 1번
- 단순선형회귀 모델은 단순한 직선을 긋기 때문에 1번 방정식의 형태로 X와 Y관계를 설명하게 됩니다.
- 1차 함수를 생각해보세요
- 다중선형회귀 모델에서 다음 중 올바른 회귀 방정식을 고르세요.
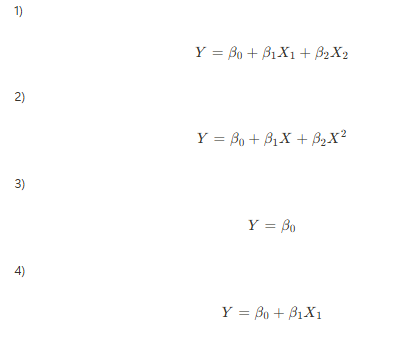
- 정답 및 해설
- 정답은 1번
- 다중선형회귀는 단순선형회귀와는 다르게 여러개의 독립변수와 Y의 관계를 설명하기 때문에 X와 그 계수가 여러개 있어야 하며 2차식이나 3차식과 같은 고차항은 존재하지 않아 평면을 만들게 되는 방정식입니다.
- 다항회귀 모델에서 독립변수가 한 개이고 X와 Y의 관계가 비선형(2차)일 때, 회귀 방정식의 형태로 올바른 것을 고르세요.

- 정답 및 해설
- 정답은 1번
- 2차원 비선형관계를 가지고 있기 때문에 2차식(X제곱) 형태를 가지고 있어야 하며 독립변수가 한개이기 때문에 각 차수(1차, 2차)마다 1개의 X를 가지고 있습니다.
- 2번의 경우 2개의 독립변수를 가진 2차식입니다.
- 스플라인 회귀는 주로 어떤 문제를 해결하기 위해 사용되나요?
- 변수 간의 상관관계를 분석하기 위해
- 데이터의 복잡한 비선형적 관계를 모델링하기 위해
- 두 그룹 간의 평균 차이를 비교하기 위해
- 범주형 변수를 처리하기 위해
- 정답 및 해설
-
- 변수 간의 상관관계를 분석하기 위해 정답은 2번
- 데이터의 복잡한 비선형적 관계를 모델링하기 위해
- 두 그룹 간의 평균 차이를 비교하기 위해
- 범주형 변수를 처리하기 위해
- 스플라인 회귀는 데이터의 복잡한 비선형적 관계(특히, 시간에 따라 비선형관계가 계속 바뀌는)를 모델링하기 위해 사용됩니다. 이를 통해 독립변수와 종속변수 간의 비선형적 패턴을 더 잘 설명할 수 있습니다.
-
https://teamsparta.notion.site/5840cbe0537a417f882e8b7600241104
[스파르타코딩클럽] 상관관계 | Notion
[수업 목표]
teamsparta.notion.site
비모수 상관계수 / 피어슨으로 쉽게 볼 수 없을 때 사용
스피어만 상관계수
- 두 변수의 순위 간의 일관성을 측정
- 켄달의 타우 상관계수 보다 데이터 내 편차와 에러에 민감
_ 는 P값 넣어서 P값 확인할 수 있음.
오차에 더 민감.
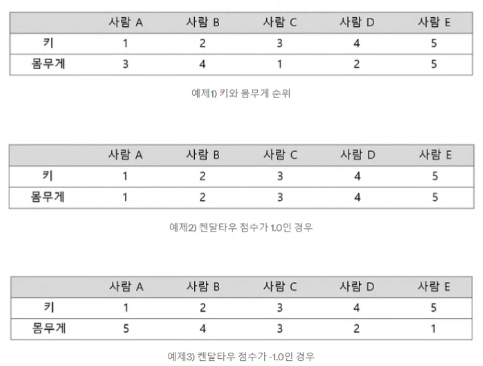
켄달의 타우
- 순위 간의 일치 쌍 및 불일치 쌍의 비율을 바탕으로 계산
- ex) 예를들어 사람의 키와 몸무게에 대해 상관계수를 알고자 할 때 키가 크고 몸무게도 더 나가면 일치 쌍에 해당, 키가 크지만 몸무게가 더 적으면 불일치 쌍에 해당 이들의 개수 비율로 상관계수를 결정
예시 더.
상호정보 상관계수
- 두 변수 간의 상호 정보를 측정
- 변수 간의 정보 의존성을 바탕으로 비선형 관계를 탐지
- 서로의 정보에 대한 불확실성을 줄이는 정도를 바탕으로 계산
- 범주형 데이터에 대해서도 적용 가능
- 상호정보 상관계수를 그림으로 확인해보기
- 보라색 점들은 X와 Y 간의 비선형 관계를 나타냄
- 상호 정보 값은 0.90으로 표시되어 있으며, 이는 두 변수 간의 강한 비선형 의존성을 의미
연습문제
✔️ 이번에 배운 내용을 다시 정리하기 위해 연습문제를 풀어봅시다! (정답 해설을 보지 않고 풀어보세요!)
- 피어슨 상관계수(Pearson correlation coefficient)의 의미를 설명하세요.
- 두 변수 간의 비선형 관계를 측정한다.
- 두 변수 간의 선형 관계를 측정한다.
- 두 변수 간의 독립성을 측정한다.
- 두 변수 간의 비모수 관계를 측정한다.
- 정답 및 해설
-
- 두 변수 간의 비선형 관계를 측정한다. 정답은 2번
- 두 변수 간의 선형 관계를 측정한다.
- 두 변수 간의 독립성을 측정한다.
- 두 변수 간의 비모수 관계를 측정한다.
- 피어슨 상관계수는 두 변수 간의 선형 관계를 측정하는 통계량입니다.
-
- 비모수 상관계수(non-parametric correlation coefficient)의 대표적인 예로 옳지 않은 것을 고르세요.
- 피어슨 상관계수
- 스피어만 상관계수
- 켄달의 타우 상관계수
- 정답 없음
- 정답 및 해설
- 정답은 1번
- 피어슨 상관계수
- 스피어만 상관계수
- 켄달의 타우 상관계수
- 정답 없음
- 비모수 상관계수는 데이터의 분포에 대한 가정을 하지 않는 상관계수입니다. 스피어만 상관계수와 켄달의 타우 상관계수가 비모수 상관계수의 예입니다.
- 정답은 1번
- 상호정보(Mutual Information) 상관계수의 의미를 설명하는 것을 모두 고르세요.
- 두 변수 간의 선형 관계를 측정한다.
- 두 변수 간의 비선형 관계를 측정한다.
- 두 변수 간의 상호 정보를 측정한다.
- 두 변수 간의 독립성을 측정한다.
- 정답 및 해설
-
- 두 변수 간의 선형 관계를 측정한다. 정답은 2번, 3번
- 두 변수 간의 비선형 관계를 측정한다.
- 두 변수 간의 상호 정보를 측정한다.
- 두 변수 간의 독립성을 측정한다.
- 상호정보 상관계수는 두 변수 간의 비선형 관계를 측정하며, 상호 정보를 통해 두 변수 간의 상관성을 평가합니다.
-
https://teamsparta.notion.site/82145b884fb6464d8259494050e24dc3
[스파르타코딩클럽] 가설검정의 주의점 | Notion
[수업 목표]
teamsparta.notion.site
재현가능성
- 동일한 연구나 실험을 반복했을 때 일관된 결과가 나오는지 여부. 연구의 신뢰성을 높이는 중요한 요소
P-해킹
- 데이터 분석을 반복하여 p-값을 인위적으로 낮추는 행위
- 유의미한 결과를 얻기 위해 다양한 변수를 시도하거나, 데이터를 계속해서 분석하는 등의 방법을 포함
문제점: p-해킹은 데이터 분석 결과의 신뢰성을 저하시킴
P 해킹 조심: (여러 가설 검정 시도할 때)
데이터의 수를 늘리다보니 특정 데이터 수를 기록할때 잠깐 p값이 0.05 이하를 기록함으로 이를 바탕으로 대립가설 채택하는 것을 조심
선택적 보고
- 유의미한 결과만을 보고하고, 유의미하지 않은 결과는 보고하지 않는 행위
- 이는 데이터 분석의 결과를 왜곡하고, 신뢰성을 저하시킴
자료수집 중단 시점 결정
- 데이터 수집을 시작하기 전에 언제 수집을 중단할지 명확하게 결정하지 않으면, 원하는 결과가 나올 때까지 데이터를 계속 수집할 수 있음. 이는 결과의 신뢰성을 떨어뜨림.
예시 한글 깨짐
구글 코랩(colab) 한글 깨짐 현상 해결방법 - 테디노트
구글 코랩(colab) 한글 깨짐 현상 해결방법
구글 코랩(colab) 한글 깨짐 현상 해결방법에 대해 알아보겠습니다.
teddylee777.github.io
import matplotlib.pyplot as plt
위 코드로 해결 안 됨. -ㅁ-
아래 코드로 해결!!!
데이터 탐색과 검증 분리
검증하기 위한 데이터는 반드시 탐색할 데이터와 검증할 데이터 따로 분리 해놓아야 함!
- 데이터 탐색을 통해 가설을 설정하고, 이를 검증하기 위해 별도의 독립된 데이터셋을 사용하는 것
- 이는 데이터 과적합을 방지하고 결과의 신뢰성을 높임
탐색용 데이터 = 학습 데이터 (머신러닝)
요거 파이썬 식 이해가 잘 안 됨
from sklearn.model_selection import train_test_split
# 데이터 생성
np.random.seed(42)
X = 2 * np.random.rand(100, 1) - 1 ~ 100 랜덤하게 가져오는 행렬 (행이 100, 열이 1) - np.random 안에서 rand (정규분포 스타일, 기본적인 스타일)
y = 4 + 3 * X + np.random.randn(100, 1) - 직선형태로 그래프 그리는 임의의 데이터
# 데이터 분할 (탐색용 80%, 검증용 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
순서 train 먼저, test, x 먼저, y // test_size (전체 데이터 중에 몇 퍼센트 test 사이즈 둘 거냐, 나머지 다 train 사이즈 됨 한 개만 쓰면 됨 // random_state (seed number에 따라 패턴이 다름, 고정할 때 random_state 에 따라 달라짐, 그 숫자를 넣을 때 만큼은 똑같은 랜덤 결과..random_state = seed / 결과를 재현하고 싶을 때 시드 넘버를 고정한다.
(패턴을 통제 할 수 있다)
# 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 탐색용 데이터로 예측
y_train_pred = model.predict(X_train)
# 검증용 데이터로 예측
y_test_pred = model.predict(X_test)
# 탐색용 데이터 평가
train_mse = mean_squared_error(y_train, y_train_pred)
train_r2 = r2_score(y_train, y_train_pred)
print(f"탐색용 데이터 - MSE: {train_mse}, R2: {train_r2}")
# 검증용 데이터 평가
test_mse = mean_squared_error(y_test, y_test_pred) - MSE 오차 (낮을 수록 좋음))
test_r2 = r2_score(y_test, y_test_pred) -얼마나 해석력이 좋은가 (1이랑 가까워야 높은 것)
print(f"검증용 데이터 - MSE: {test_mse}, R2: {test_r2}")
탐색용 데이터 - MSE: 0.8476788564209705, R2: 0.7582381034538057
검증용 데이터 - MSE: 0.6536995137170021, R2: 0.8072059636181392
탐색용이 검증용보다 오차가 높다. 해석력은 검증용이 더 높다.
보통은 탐색용이 결과가 잘 나오는 편. 검증이 결과가 더 잘 안 나옴. 검증이랑 탐색용과 결과가 덜 나게 하는 것이 관건.
검증이 탐색용보다 잘 나온 거니까 검증이 잘 된 것이라고 보면 됨. ( 더 잘 나온 거니까 )
탐색용 잘 나오는 이유: 학습할 때 test 안 씀. train 데이터에 대해서는 당연히 잘 예측할 수 밖에 없음.
검증용이 중요한 거다.
추가로 통계학을 공부하기 위하여
- 여인권 교수님의 기초통계학
- 고지마 히로유키, 세상에서 가장 쉬운 통계학 입문
- 아베 마사토, 통계 101 x 데이터 분석
연습문제
✔️ 이번에 배운 내용을 다시 정리하기 위해 연습문제를 풀어봅시다! (정답 해설을 보지 않고 풀어보세요!)
- 재현 가능성(reproducibility)에 대한 설명으로 옳은 것을 고르세요.
- 재현 가능성은 동일한 연구자가 동일한 실험을 여러 번 수행하여 동일한 결과를 얻는 것을 의미한다.
- 재현 가능성은 다른 연구자가 동일한 실험 절차를 따라 실험을 수행하여 동일한 결과를 얻는 것을 의미한다.
- 재현 가능성은 데이터 분석 과정에서 발생하는 오류를 줄이기 위한 방법이다.
- 재현 가능성은 통계 분석의 정확성을 평가하는 기준이다.
- 정답 및 해설
-
- 재현 가능성은 동일한 연구자가 동일한 실험을 여러 번 수행하여 동일한 결과를 얻는 것을 의미한다. 정답은 2번
- 재현 가능성은 다른 연구자가 동일한 실험 절차를 따라 실험을 수행하여 동일한 결과를 얻는 것을 의미한다.
- 재현 가능성은 데이터 분석 과정에서 발생하는 오류를 줄이기 위한 방법이다.
- 재현 가능성은 통계 분석의 정확성을 평가하는 기준이다.
- 재현 가능성은 (내가 아닌)다른 연구자가 동일한 실험 절차를 따라 실험을 수행하여 동일한 결과를 얻는 것을 의미합니다. 이는 연구 결과의 신뢰성을 높이는 중요한 요소입니다.
-
- p-해킹(p-hacking)의 정의에 가장 가까운 것을 고르세요.
- 통계 분석에서 발생하는 오류를 수정하는 과정
- 연구자가 원하는 결과를 얻기 위해 데이터를 반복적으로 분석하고 p-value를 조작하는 행위
- 데이터를 시각화하여 결과를 해석하는 과정
- 데이터를 수집하고 분석하는 표준 절차
- 정답 및 해설
-
- 통계 분석에서 발생하는 오류를 수정하는 과정 정답은 2번
- 연구자가 원하는 결과를 얻기 위해 데이터를 반복적으로 분석하고 p-value를 조작하는 행위
- 데이터를 시각화하여 결과를 해석하는 과정
- 데이터를 수집하고 분석하는 표준 절차
- p-해킹은 연구자가 원하는 결과를 얻기 위해 데이터를 반복적으로 분석하고 p-value를 조작하는 행위로, 이는 연구 결과의 신뢰성을 저해할 수 있습니다.
-
- 선택적 보고(selective reporting)이 문제인 이유로 가장 적절한 것을 고르세요.
- 연구자가 모든 데이터를 수집하지 못할 수 있다.
- 연구자가 연구 결과를 왜곡하여 보고할 수 있다.
- 연구자가 데이터를 분석하는 방법을 모를 수 있다.
- 연구자가 통계적 방법을 사용할 수 없다.
- 정답 및 해설
-
- 연구자가 모든 데이터를 수집하지 못할 수 있다. 정답은 2번
- 연구자가 연구 결과를 왜곡하여 보고할 수 있다.
- 연구자가 데이터를 분석하는 방법을 모를 수 있다.
- 연구자가 통계적 방법을 사용할 수 없다.
- 선택적 보고는 연구자가 자신에게 유리한 결과만을 선택적으로 보고하는 행위로, 이는 연구 결과의 왜곡을 초래할 수 있습니다.
-
- 자료수집 중단 시점을 결정할 때 발생할 수 있는 문제는 무엇인가요?
- 데이터 수집 비용이 증가한다.
- 데이터의 신뢰도가 높아진다.
- 연구자의 편향이 결과에 영향을 미칠 수 있다.
- 데이터의 다양성이 감소한다.
- 정답 및 해설
-
- 데이터 수집 비용이 증가한다.
- 데이터의 신뢰도가 높아진다. 정답은 3번
- 연구자의 편향이 결과에 영향을 미칠 수 있다.
- 데이터의 다양성이 감소한다.
- 자료수집 중단 시점을 연구자가 임의로 결정할 경우, 연구자의 편향이 결과에 영향을 미칠 수 있습니다. 이는 연구의 신뢰성을 떨어뜨릴 수 있습니다.
-
- 데이터 탐색(exploration)과 검증(validation)을 분리하는 이유로 가장 적절한 것을 고르세요.
- 데이터 탐색과 검증을 분리하면 데이터 분석 과정이 단순해진다.
- 데이터 탐색과 검증을 분리하면 데이터 분석 과정에서 발생하는 오류를 줄일 수 있다.
- 데이터 탐색과 검증을 분리하면 과적합(overfitting)을 방지하고 모델의 일반화 성능을 높일 수 있다.
- 데이터 탐색과 검증을 분리하면 데이터 수집 비용을 절감할 수 있다.
- 정답 및 해설
-
- 데이터 탐색과 검증을 분리하면 데이터 분석 과정이 단순해진다.
- 데이터 탐색과 검증을 분리하면 데이터 분석 과정에서 발생하는 오류를 줄일 수 있다. 정답은 3번
- 데이터 탐색과 검증을 분리하면 과적합(overfitting)을 방지하고 모델의 일반화 성능을 높일 수 있다.
- 데이터 탐색과 검증을 분리하면 데이터 수집 비용을 절감할 수 있다.
- 데이터 탐색과 검증을 분리하면 과적합을 방지하고, 모델이 새로운 데이터에 대해 얼마나 잘 일반화될 수 있는지를 평가할 수 있습니다.
-
'강의 > 통계학' 카테고리의 다른 글
| [통계 라이브세션 1] 주요 강의내용 정리 (0) | 2024.11.13 |
|---|---|
| [통계학 기초] 1강, 2강, 3강 (2) | 2024.11.11 |
