
rubus0304 님의 블로그
[머신러닝 개인과제 해설] 본문
[4기] 통계 + 머신러닝 개인 과제 | Notion
제출 마감 : 2024. 12. 11 (수) 15:00 까지
teamsparta.notion.site
필수 1. 기초통계
- statistics csv 파일을 읽고, 성별 Review Rating 에 대한 평균과 중앙값을 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요.
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
df=pd.read_csv("statistics.csv")
#평균
mean = df.groupby(['Gender'])['Review Rating'].mean().reset_index()
rounded_mean = round(mean, 2)
print(rounded_mean)
#중앙값
median = df.groupby(['Gender'])['Review Rating'].median().reset_index()
rounded_median = round(median, 2)
print(rounded_median)
df.groupby(['Gender'])['Review Rating'].agg(['mean','median']).round(2),reset_index
평균적으로나 중앙값적으로나 남성의 리뷰평점이 높다.
데이터가 치우쳐져있지 않다.
필수 2. 통계적 가설검정
- 성별, Review Rating 컬럼에 대한 T-TEST 를 진행해주세요.
- 귀무가설과 대립가설을 작성해주세요.
- t-score, P-value 를 구해주세요.
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
df=pd.read_csv("statistics.csv")
#T-test 가설 설정하기
#귀무가설: 남성과 여성의 평균 리뷰점수에 차이가 없을 것이다.
#대립가설: 남성과 여성의 평균 리뷰점수에 차이가 있을 것이다.
df.groupby(['Gender'])['Review Rating'].mean().reset_index()
# 데이터 분리
# mask method
mask = (df['Gender']=='Male')
mask1 = (df['Gender']=='Female')
m_df = df[mask]
f_df = df[mask1]
# 리뷰점수 컬럼만 가져오기
m_df = m_df[['Review Rating']]
f_df = f_df[['Review Rating']]
t, pvalue = stats.ttest_ind(f_df, m_df)
t, pvalue
결과해석: P-value 값이 0.05보다 크므로, 연관성이 없다고 추정할 수 있다.
따라서, 대립가설 기각되고, 귀무가설 채택
즉, 성별에 따라 평균 리뷰점수의 차이는 없을 것이다. (성별과 리뷰점수는 서로 유의미한 관계를 보이지 않는다.)
필수 3. 통계적 가설검정2
- Color, Season 컬럼에 대한 카이제곱 검정을 진행해주세요.
- 귀무가설과 대립가설을 작성해주세요.
- 두 범주형 자료의 빈도표를 만들어주세요. 이를 코드로 작성하여 기재해주세요.
- 카이제곱통계량, P-value 를 구해주세요.
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
df=pd.read_csv("statistics.csv")
#카이제곱 검정:
#가설 설정
#귀무가설: Color와 Season 에는 관련성이 없을 것이다. (독립적일 것이다)
#대립가설: Color와 Season 에는 관련성이 있을 것이다.
df.groupby(['Color', 'Season'])['Customer ID'].count().reset_index()
#카이제곱검정: 빈도표 그리기
result = pd.crosstab(df['Color'],df['Season'])
result
#chi2_coontingency를 통해, 카이제곱통계량, p-value를 출력가능
stats.chi2_contingency(observed=result)
#각 값들을 별도로 보기
#카이제곱 검정 통계량, p-value, 자유도를 확인할 수 있다.
stats.chi2_contingency(observed=result)[0]
stats.chi2_contingency(observed=result)[1]
여기서 p-value 값은 0.05 보다 높으므로, 연관성이 없다고 추정가능.
귀무가설 채택, 대립가설 기각. 즉, Color와 Season에는 관련성이 없을 것이다. (유의미한 관계가 있을 것으로 보이지 않는다.)
필수 4. 머신러닝1
- 아래와 같은 데이터가 있다고 가정하겠습니다.데이터를 바탕으로 선형 회귀 모델을 훈련시키고, 회귀식을 작성해주세요.
- 독립 변수(X): 광고예산 (단위: 만원)
- 종속 변수(Y): 일일 매출 (단위: 만원)
- X=[10, 20, 30, 40, 60, 100]
- Y=[50, 60, 70, 80, 90, 120]
- 회귀식을통해, 새로운 광고예산이 1,000만원일 경우의 매출을 예측(계산)해주세요.
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
#독립 변수(X): 광고 예산 (단위: 만원)
#종속 변수(Y): 일일 매출 (단위: 만원)
X = [10,20,30,40,60,100]
Y = [50,60,70,80,90,120]
#dictionary 형태로 데이터 생성
df = pd.DataFrame({'광고예산 (만원)': X, '일일매출 (만원)': Y})
#광고예산과 일일매출간의 산점도 (scatter plot)
sns.scatterplot(data = df, x='광고예산 (만원)', y='일일매출 (만원)')
plt.title('광고예산 vs 일일매출')
plt.xlabel('광고예산(만원)')
plt.ylabel('일일매출(만원)')
plt.show()
#선형회귀 훈련
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
type(model_lr)
# DataFrame[]: series (데이터 프레임의 컬럼)
# DataFrame[[]]: DataFrame
X = df[['광고예산 (만원)']]
y = df[['일일매출 (만원)']]
#데이터 훈련
model_lr.fit(X = X, y = y)
#예측
x=np.array(1000)
x=x.reshape(-1,1)
y_pred_tip2 = model_lr.predict(x)
y_pred_tip2
model_lr.coef_
model_lr.intercept_
#회귀식
y = 0.75625X + 45.5625
새로운 광고예산이 1,000만원일 경우의 매출: 801.8125원
X = np.array([10, 20, 30, 40, 60, 100]).reshape(-1. 1)
Y = np.array([50, 60, 70, 80, 90, 120])
# 모델 훈련
model = LinearRegression( )
model .fit(X, Y)
coef, intercept = model.coef_[0], model.intercept_
print (f"회귀식: Y = {coef: .2f} X + {intercept_}
도전 1. 머신러닝2
- Review Rating, Age, Previous Purchases 컬럼을 활용하여, 고객이 할인(Discount Applied)을 받을지 예측하는 RandomForest모델을 학습시켜 주세요. 그리고 모델 정확도를 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요.
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- RandomForestClassifier 를 활용하여 모델 학습을 진행해주세요. random_state는 42로 설정해주세요.
- 참고) https://www.ibm.com/kr-ko/topics/random-forest
랜덤 포레스트란 무엇인가요? | IBM
랜덤 포레스트는 일반적으로 사용되는 머신 러닝 알고리즘으로, 여러 의사결정 트리의 아웃풋을 결합하여 단일 결과에 도달합니다.
www.ibm.com
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
accuracy = rf_model.score(X_test, y_test)
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier,plot_tree
Random_df = pd.read_csv('statistics.csv')
Random_df.info()
X_features = ['Review Rating','Age','Previous Purchases']
# Discount Applied: LabelEncoder
le = LabelEncoder()
Random_df['Discount Applied'] = le.fit_transform(Random_df['Discount Applied'])
X = Random_df[X_features]
y = Random_df['Discount Applied']
model_dt = DecisionTreeClassifier()
model_dt.fit(X,y)
#시각화
plt.figure(figsize = (10,5))
plot_tree(model_dt, feature_names=X_features, class_names=['Not Discounted','Discounted'], filled= True)
plt.show()
#랜덤포레스트 훈련
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,f1_score
from sklearn.model_selection import train_test_split
# train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, shuffle=True, stratify=y, random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_rf.fit(x_train,y_train)
#랜덤포레스트_예측
y_rf_pred = model_rf.predict(x_valid)
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred).round(3)
f1 = f1_score(y_true,y_pred).round(3)
print(model_name, 'acc 스코어는: ',acc, 'f1_score는: ', f1)
get_score('rf ',y_valid,y_rf_pred)
#정확도만
accuracy = model_rf.score(x_valid, y_valid)
accuracy
모델정확도: 0.511 (f1_score는 0.362 로 낮으므로 클래스별 갯수 차이가 있음)

도전 2. 머신러닝3
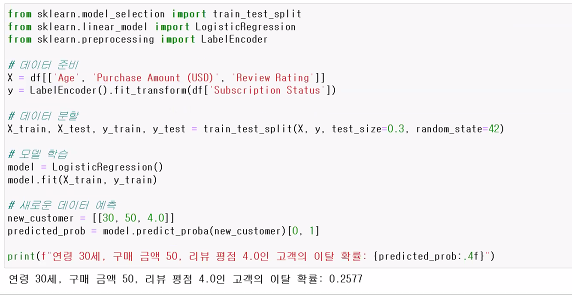
- Subscription Status 컬럼을 종속변수로 사용하여 고객의 이탈 여부를 예측하는 로지스틱 회귀 모델 학습을 진행해주세요. Age, Purchase Amount, Review Rating을 활용하여 모델을 훈련한 후, 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0인 고객의 이탈 확률을 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요.
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0 인 고객을 new_customer 라는 변수에 지정해주세요. 1차원이 아닌 이중 대괄호[[...]]로 지정해주세요. (모델 입력 형식은 2차원 배열이어야 하므로)
- model.predict_proba 를 사용하여 이탈 확률을 구해주세요.
- predict_proba의 반환값**:** 모델이 각 클래스에 속할 확률을 계산합니다. 결과는 다음과 같은 배열로 반환됩니다.
- [[P(클래스 0), P(클래스 1)]]
- P(클래스 0): 이 고객이 이탈하지 않을 확률.
- P(클래스 1): 이 고객이 이탈할 확률.
- 예시) predict_proba(new_customer)가 아래와 같이 반환되었다면
- [[0.73, 0.27]]
- -----------------------------------------------------------------
- 0.73: 이 고객이 이탈하지 않을 확률입니다.
- 0.27: 이 고객이 이탈할 확률입니다.
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta
logic_df = pd.read_csv('statistics.csv')
#로지스틱회귀 인코딩
X_features = ['Age','Purchase Amount (USD)','Review Rating']
le = LabelEncoder()
logic_df['Subscription Status'] = le.fit_transform(logic_df['Subscription Status'])
X = logic_df[X_features]
y = logic_df['Subscription Status']
#로지스틱회귀 훈련
from sklearn.linear_model import LogisticRegression
# train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, shuffle=True, stratify=y, random_state=42)
model_lor = LogisticRegression()
model_lor.fit(x_train,y_train)
#로지스틱회귀 예측
y_lor_pred = model_lor.predict([[30,50,4.0]])
y_lor_pred
#이탈예측 확률
model_lor.predict_proba([[30,50,4.0]])
연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0인 고객은 0 (구독안함) 확률이 0.73로 더 높다
통계야 놀자 4회차
'Data Analyst > 라이브세션' 카테고리의 다른 글
| [태블로 강의] (0) | 2024.12.13 |
|---|---|
| [비즈니스 매트릭스 기초] (0) | 2024.12.11 |
| [머신러닝 군집] (0) | 2024.11.28 |
| [머신러닝 빌드업2] 지도, 비지도, 강화학습 (0) | 2024.11.25 |
| [머신러닝 빌드업 1] 머신러닝 개념 (0) | 2024.11.21 |


