
rubus0304 님의 블로그
[Python 개인과제] 8문제 풀며 알고리즘 복습하기 본문
[4기] Python 개인 과제 | Notion
개인 과제 안내
teamsparta.notion.site
필수 문제 1: 숫자 리스트의 평균을 계산하는 방법
배경: 전자 상거래 플랫폼에서 고객의 평균 주문을 계산해야 합니다. 이를 위해 숫자 리스트의 평균을 계산하는 방법을 연습합니다.
목표: 주어진 숫자 리스트의 평균을 계산하는 함수를 작성하세요.
numbers = [10, 20, 30, 40, 50]
def calculate_avg(numbers):
total_avg = sum(numbers) / len(numbers)
return total_avg
total_avg = calculate_avg(numbers)
print("숫자들의 평균:",total_avg)숫자들의 평균: 30.0
아니.. 수업에선 print("Hello, world") 짠 ~ ! 이것부터 배우기 시작하는데, 알고리즘 코드카타고 과제 1번부터 막 def 함수 return 부터 쓰냐고.. ㅠ0ㅠ 광광광광광광 당황스럽다구요 쒸익쒸익.. 수업시간에 언급이라도 해주시지.. 문제는 이것부터 나와요 여러분 ~^ㅁ^ 마음에 준비도 안 됬는데 막 막 막 ㅠㅠ
혼자서 블로랑 수업자료랑 막 찾으면서 막 이러다 뒤죽박죽 알게 되면 어떡하지 마음도 졸이고 문제풀면서 알아가는 파이썬 알고리즘 후엥 ㅠ0ㅠ 어려버어려붜 어렵다구!! 원리도 안 알려주고 뭔가 앙???? 혼자 찾아 학습을 떠나면서 다들 알게 되신거냐고여 파이썬 선배님들ㅠㅠㅠㅠ
numpy mean!!! 있음
문제 2: 가장 낮은 기온과 가장 높은 기온을 활용하여 일교차를 함수로 작성
배경: 기상청에서는 하루 동안의 가장 높았던 기온과 가장 낮았던 기온을 확인하고 일교차를 보고하고자 합니다.
목표: 하루 동안 기록된 기온 목록을 받아, 가장 낮은 기온과 가장 높은 기온을 활용하여 일교차를 함수로 작성하세요.
numbers = [10, 20, 30, 40, 50]
def calculate_diff_temperature(numbers):
calculate_diff_temp=max(numbers)-min(numbers)
return calculate_diff_temp
diff_temp= calculate_diff_temperature(numbers)
print("일교차", diff_temp)일교차 40
흠 그래도 첫 번째 꺼 원리 이해하고 나니까 두 번재 꺼는 바로 풀리는구만
문제 3: 가장 많이 판매된 제품의 이름과 수량을 반환하는 함수를 작성
배경: 한 소매점에서는 다양한 제품을 판매하고 있습니다. 매월 판매된 제품들의 목록과 각 제품의 판매수량이 기록됩니다. 이 데이터를 분석하여 가장 많이 판매된 제품을 찾아내려고 합니다.
목표: 제푸 이름과 해당 제품의 판매 수량을 담은 딕셔너리로 구성되어 있음
def find_top_seller(sales_data):
values = sales_data.values()
top_product=max(sales_data, key=sales_data.get)
max_sales=max(values)
return top_product, max_sales
sales_data = {
"apple": 50,
"orange": 2,
"banana": 30
}
print("가장 많이 판매된 제품과 수량:", find_top_seller(sales_data))가장 많이 판매된 제품과 수량: ('apple', 50)
values 꺼내오는 함수. values = 딕셔너리.values() / max_sales = max(values)
key 값 꺼내오는 함수 (max, min 안에서 ex) max(딕셔너리, key=딕셔너리.get)
** 원래 get 은 값 꺼내오는 함수. ex) age=딕셔너리. get('key값')
print(age) 출력: 30//
**
items( ) Key, 값 같이 가져올 수 있음
max_value = 0
for key. value
** 더 심플 (확인하기)
max_key = max ~
문제4: 사칙연산을 수행할 수 있는 프로그램 구현
배경: 컴퓨터 과학 수업에서 학생들은 기본적으로 프로그래밍 원리를 익히고, 실제 생활에 적용할 수 있는 간단한 프로그램을 만드는 연습을 합니다. 간단한 계산기를 만들어서 사칙연산을 수행할 수 있는 프로그램을 구현하는 것은 기본적인 프로그래밍 실습에 적합합니다.
목표: 두 숫자와 연산자를 입력받아, 해당 연산을 수행하고 결과를 반환하는 함수를 작성하세요.
데이터:
- num1, num2: 숫자 입력값
- operator: 문자열 형태의 연산자('+', '-', '*', '/')
def simple_calculator(num1, num2, operator):
if operator == "+":
return num1 + num2
elif operator == "-":
return num1 - num2
elif operator == "*":
return num1 * num2
elif operator == "/":
return num1 / num2
pass
print(simple_calculator(10,5, '+'))
print(simple_calculator(10, 5, '-'))
print(simple_calculator(10, 5, '*'))
print(simple_calculator(10, 5, '/'))
15
5
50
2.0
간단계산 함수 만들기 (if - elif - return ) def - pass
def simple_calculator (num1, num2, operator):
if operator == "+":
return num1 + num2
...
pass
print (simple_calculator(10, 5, "+"))
** 어랏.. 왜 error 되지
** Try except 구문 미리 짜놓으면 에러부문 넘어가고 진행할 수 있음
문제5: 이메일 주소가 올바른 형식을 갖추고 있는지 판단하는 프로그램 구현
배경: 당신은 회사의 고객 데이터베이스를 관리하고 있습니다. 데이터베이스에 저장된 고객의 이메일 주소가 유효한 형식을 갖추고 있는지 검증하는 작업이 필요합니다.
목표: 문자열 형태의 이메일 주소 목록을 분석하여, 각 이메일 주소가 올바른 형식을 갖추고 있는지 판단하는 프로그램을 작성하세요.
데이터:
- 이메일 주소는 문자열 리스트로 제공됩니다.
- 올바른 이메일 주소의 형식은 다음과 같습니다:
- 하나의 '@' 기호를 포함해야 합니다.
- '@' 기호 앞에는 하나 이상의 문자가 있어야 합니다.
- '@' 기호 뒤에는 도메인명이 와야 하며, 도메인명은 '.'을 포함한 하나 이상의 문자로 구성되어야 합니다.
요구사항:
- 각 이메일 주소가 올바른 형식을 갖추고 있는지 검사합니다. (문자열 메소드 사용)
- 올바른 형식의 이메일 주소인 경우, "유효한 이메일 주소입니다."를 출력합니다.
- 올바르지 않은 형식의 경우, "유효하지 않은 이메일 주소입니다."를 출력합니다.
def validate_emails(email_list):
for email in email_list:
#하나의 '@'기호를 포함
if "@" in email:
#'@'기호 앞에 하나 이상의 문자 必
parts= email.split("@")
if len(parts) == 2:
username= parts[0],
domain = parts[1]
#'@'기호 뒤에 도메인명, 도메인명은 '.'을 포함한 하나 이상의 문자
if username and domain:
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
else: print(f"{email} 유효하지 않은 이메일 주소입니다.")
else: print(f"{email} 유효하지 않은 이메일 주소입니다.")
email_list = [
"example@example.com",
"wronggemail@com",
"anotherexample.com",
"correct@email.co.uk"
]
validate_emails(email_list)
example@example.com 유효한 이메일 주소입니다.
wronggemail@com 유효하지 않은 이메일 주소입니다.
anotherexample.com 유효하지 않은 이메일 주소입니다.
correct@email.co.uk 유효한 이메일 주소입니다.
와 이 문제에서 알게 된 내용이 어마무시하다..
1. for 반복문 continue 이해
print()
a=[1,2,3]
for i in a:
print(i * 1)
if i == 1:
continue
print (i*100)#출력::
1
2
200
3
300
" 변수 i 가 1일 경우, 다음 print 까지 가지 않고 list a의 다음 값으로 반복하러 감. 근데 2부터는 i 가 1이 아니므로, 다음 print (i*100) 을 계산해서 출력하는 것임." ** 이 때 들여쓰기 간격 유으!! 2번째 Print는 for문 안에 포함되어있어야함!!
마찬가지로, 위에 문제 5 를 else 대신 continue를 넣을 수 있음!
def validate_emails(email_list):
for email in email_list:
# '@' 기호가 있는지 확인
if "@" in email:
# '@' 기호를 기준으로 문자열을 두 부분으로 나누기
parts = email.split('@')
# 나눠진 부분이 정확히 두 개인지 확인
if len(parts) == 2:
username, domain = parts
# 두 부분이 모두 비어있지 않은지 확인
if username and domain:
# 도메인에 '.'이 포함되어 있는지 확인
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
continue
print(f"{email} 유효하지 않은 이메일 주소입니다.")
# 이메일 목록
email_list = [
"example@example.com",
"wrongemail@com",
"anotherexample.com",
"correct@email.co.uk"
]
# 이메일 유효성 검사 실행
validate_emails(email_list)
continue 를 쓴 경우 유효한 이메일 주소인 경우 밑에 유효하지 않은 이메일 주소 print 로 안 넘어가고 바로 email.list 의 다음 이메일로 반복하러 감. 근데 그렇게 넘어가다 else 처럼 유효한 이메일이 아닌 경우, 다음 print (유효지 않은 이메일) 을 실행!
2. 파이썬 스러운 구문
username, domain = parts
if "@" in email:
#'@'기호 앞에 하나 이상의 문자 必
parts= email.split("@")
if len(parts) == 2:
username, domain = parts
여기서, email 을 @ 앞 뒤로 나누기 위해 parts 를 만들어 parts = email.split("@"), @를 기준으로 분리시킴.
@ 앞에 하나 이상의 문자가 있어야하니까, if len(parts) == 2: 로 2부분이 되는 경우로 조건 검.
그리고 그 나눠준 애들을 지명할 때,,,
원래는 보통 다른 언어에서도 그렇고, 이렇게 하는데,,
username = parts[0],
domain = a[1]
if "@" in email:
#'@'기호 앞에 하나 이상의 문자 必
parts= email.split("@")
if len(parts) == 2:
username= parts[0],
domain = parts[1]
파이썬에서만,
username, domain = parts
이렇게 해서 그냥 parts의 앞 부분은 username, 두 번째 부분은 domain으로 지정해 줄 수 있음! (굉장히 파이썬 스러운 것이라함!)
3. if : if : 중복으로 쓸 수 있음
~ 경우이면서 ~ 경우 ! 대신 들여써야함
if username and domain:
if "." in domain:
근데 사실 보니까 if 문 전체가 다 들여쓰기해서 조건 엄청 주고 마지막 if 뒤에 print 가 있음
if "@" in email:
#'@'기호 앞에 하나 이상의 문자 必
parts= email.split("@")
if len(parts) == 2:
username= parts[0],
domain = parts[1]
#'@'기호 뒤에 도메인명, 도메인명은 '.'을 포함한 하나 이상의 문자
if username and domain:
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
4. else 구문 과 continue 구문 차이
와.. else구문일 때 email이 3개만 나오고, continue는 이메일이 4개 나오는걸 과제 제출 뒤에 발견..!!
확인해보니 else를 사용한 식에서는 마지막 조건 "."이 도메인에 포함되었을 때 유효한 ㅣ메일 주소고 아닐 때의 경우는 포함되지 않았다.
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
else: print(f"{email} 유효하지 않은 이메일 주소입니다.")
else 구문 뒤에 원래 있던 거는 들여쓰기가 첫 번째 if 에 있기 때문에 여기서는 마지막 if 를 위한 else를 한번 더 써줘야 했다.
if "@" in email:
#'@'기호 앞에 하나 이상의 문자 必
parts= email.split("@")
if len(parts) == 2:
username= parts[0],
domain = parts[1]
#'@'기호 뒤에 도메인명, 도메인명은 '.'을 포함한 하나 이상의 문자
if username and domain:
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
else: print(f"{email} 유효하지 않은 이메일 주소입니다.")
else: print(f"{email} 유효하지 않은 이메일 주소입니다.")
반면, continue의 경우, 마지막 if문 까지 싹 다 포함해서 안 될 경우, 유효하지 않은 이메일 주소 print 가 나온다.
def validate_emails(email_list):
for email in email_list:
# '@' 기호가 있는지 확인
if "@" in email:
# '@' 기호를 기준으로 문자열을 두 부분으로 나누기
parts = email.split('@')
# 나눠진 부분이 정확히 두 개인지 확인
if len(parts) == 2:
username, domain = parts
# 두 부분이 모두 비어있지 않은지 확인
if username and domain:
# 도메인에 '.'이 포함되어 있는지 확인
if "." in domain:
print(f"{email} 유효한 이메일 주소입니다.")
continue
print(f"{email} 유효하지 않은 이메일 주소입니다.")
** if username and domain:
공백인지 아닌지 확인하는 구문
문제 6: 각 문자가 등장하는 빈도를 함께 출력하는 프로그램 구현
배경: 당신은 대규모 텍스트 데이터를 분석하는 프로젝트를 진행하고 있습니다.
텍스트 데이터에서 특정 패턴을 찾아내는 작업을 수행해야 합니다. 이번 작업에서는 중복된 문자를 제거하고 각 문자가 한 번씩만 나타나게 하는 프로그램을 작성하는 것이 목표입니다. 하지만 각 문자는 처음 등장한 순서를 유지해야 하며, 추가적으로 각 문자가 등장하는 빈도를 함께 계산해야 합니다.
목표: 주어진 문자열에서 중복된 문자를 제거하고, 각 문자가 처음 등장한 순서대로 한 번씩만 나타나게 하며, 각 문자가 등장하는 빈도를 함께 출력하는 프로그램을 작성하세요.
데이터:
- 입력 문자열은 알파벳 대문자와 소문자, 숫자, 공백으로 구성될 수 있습니다.
요구사항:
- 주어진 문자열에서 중복된 문자를 제거합니다.
- 각 문자가 처음 등장한 순서를 유지합니다. -> 반복문 - 딕셔너리에 쏙
- 각 문자가 등장하는 빈도를 함께 출력합니다.
- 결과는 (문자, 빈도수) 형태의 튜플 리스트로 반환합니다
def remove_duplicates_and_count(s):
frequency = {} # 각 문자의 빈도수를 저장할 딕셔너리
for char in s: # 각 문자의 빈도수 업데이트
if char in frequency.keys(): # frequency 딕셔너리의 keys 값에 문자가 들어가면 1을 더해
frequency[char] += 1 # 딕셔너리 요소 추가하기 (값 수정도 똑같음)
else: frequency[char] = 1
result_with_frequency = [] # for문 반복해서 들어올 리스트.
for key, value in frequency.items(): #모든 key-값 쌍을 (키,값) 튜플로 반환.
result_with_frequency.append((key, value)) #key, value 추가
return result_with_frequency
input_string = "abracadabra123321" #(예시문자열)
result = remove_duplicates_and_count(input_string)
print(result)
list ( ) 로 잡으면 튜플!
- For 문으로 문자열 s 를 char 라는 변수에 넣어서 돌리기.
- 만약 if char in frequency.keys( ): (딕셔너리의 키 값들을 추출) 에 char 문자가 있다면, 해당 키 값에 빈도수 1씩 증가시켜준다. 아니면 1로 반환.
- for keys, value in frequencty.items( ): 키 & 값 이 모두 출력. 각각 변수 key, value 에 저장시켜 돌려줌.
- 그래서 결과 리스트에 각 문자의 빈도수를 업데이트 해줌.
(수업들으면서 한번 더 이해해보자)
딕셔너리 집어넣기
a_dict = { }
a_dict['가'] = 1
a_dict['나'] =2
dict_keys ( )
dict_values ( )
문제 7 : 경기 동안 각 선수가 이동한 총 누적 거리를 계산하는 프로그램 구현
배경: 축구 경기 데이터 분석가로서, 선수들의 위치 데이터를 활용하여 그들의 활동 범위와 이동 효율성을 계산하는 것은 팀 전략을 세우는 데 중요합니다. 선수들의 이동 패턴을 분석하고 이를 통해 그들의 총 누적 이동 거리를 계산하여 선수의 활동량을 평가할 수 있습니다.
목표: 선수들의 위치 데이터가 주어졌을 때, 해당 데이터를 분석하여 경기 동안 각 선수가 이동한 총 누적 거리를 계산하는 프로그램을 작성하세요.
데이터:
- 위치 데이터는 선수의 이름과 그에 따른 위치 좌표의 리스트를 포함하는 딕셔너리 형태로 제공됩니다. 각 좌표는 (x, y) 튜플로 표현됩니다.
- 선수는 경기 동안 여러 번 위치가 변경될 수 있으며, 각 위치는 이전 위치에서의 이동 거리를 기록합니다.
요구사항:
- 유클리드 거리 공식을 사용하여 각 위치 변경 시 이동 거리를 계산합니다.
- 각 선수별로 경기 동안 이동한 총 누적 거리를 출력합니다.
** 유클리드 거리 공식
def euclidean_distance(pt1, pt2):
distance = 0
for i in range(len(pt1)):
distance += (pt1[i] - pt2[i]) ** 2
return distance ** 0.5두 점 사이의 거리 공식
본 포스팅에서는 두 점 사이의 거리를 구하는 여러가지 방법을 알아본다. 그런데 거리(distance)를 왜 구해야 할까? 거리는 일종의 유사도(similarity) 개념이기 때문이다. 거리가 가까울수록 그 특성(
velog.io
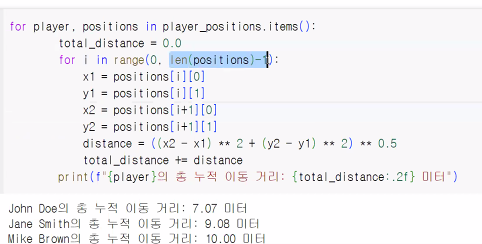
** 소숫점 두 자리까지만 나오게하기: 해당 컬럼: .2f
import math
def calculate_total_distances(player_positions):
for player, position in player_positions.items():
total_distance = 0
for i in range(1, len(position)):
x1, y1 = position[i-1]
x2, y2 = position[i]
distance = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
total_distance += distance
print(f"{player}의 총 누적 이동 거리: {total_distance:.2f} 미터")
player_positions = {
"john Doe": [(0, 0), (1, 1), (2, 2), (5, 5)],
"Jane Smith": [(2, 2), (3, 8), (6, 8)],
"Mike Brown": [(0, 0), (3, 4), (6, 8)]
}
calculate_total_distances(player_positions)
거리 계산 - 머신러닝에서 나옴
가까운 데이터냐 먼 데이터냐 판단 할 때 또 나옴
유클리디안 - 피타고라스 (a2 + b2 = c2)
맨해튼 - 절대값
코사인 거리 - 삼각함수
커뮤니티 분석 대 필요!
인덱싱
positions [~ ]
total_distance = 0 초기값 (반복위해)
unpacking!! a1, a2, a3 = a 로 -> a = [a1, a2, a3] packing
math. sqrt (루트)
numpy. sqrt
** 0.5 는 여기서 안 함 (루트 했으니까)
문제 8 : 언어를 확인하여 암호를 해독하는 프로그램 구현
문제배경
르탄이는 팀스파르타의 대표 캐릭터 입니다 :)
어느날, 르탄이가 당신의 길을 막고 암호를 말할테니 이 암호를 풀어야 길을 비켜준다고 합니다.
르탄이가 알려주는 암호는 한글과 영어로 쓰여있는 숫자들을 나열한 것인데 이를 알려주면 여러분이 아라비아 숫자 형태로 바꾸어서 르탄이한테 다시 알려주어야 합니다.
또한 숫자로 바꾸기 전에 한글로 이루어진 숫자가 몇개인지, 영어로 이루어진 숫자가 몇개인지를 함께 알려주어야 합니다.
목표: 이렇게 영어와 한글이 섞인 숫자들이 문자열 형태로 주어집니다. 이를 아라비아 숫자형태로 바꾸어서 출력하고, 한글로 적인 숫자의 개수, 영어로 적인 숫자의 개수를 차례로 반환하는 함수를 완성해주세요!
제한사항:
참고로, 암호로 주어질 수 있는 영어숫자와 한글숫자의 범위는 아래와 같습니다.
- 영어숫자의 범위 : zero ~ nine
- 한글숫자의 범위 : 영 ~ 구
또한 입출력 값은 다음의 범위를 가집니다.
- 입력으로 주어지는 문자의 길이는 1에서 4까지 가질 수 있습니다.
- 출력값으로 나올 수 있는 정수는 0~9999 입니다
1. 딕셔너리 활용
한글
영어
for item in en_num.items( ):
word = item[0]
num = itme[1]
s= s.replace(word, str(num))
for item in ko_num.items( ):
word = item[0]
num = itme[1]
s= s.replace(word, str(num))
s
2. 숫자 몇 개인지 : split 사용해보기
[갯수 세는 메커니즘 (코딩 테스트에서 자주 나옴) ]
number = 0 (갯수 담을 초기값 설정)
for i in [1,2,3,4,5]
number += 1 (반복 실행 될 때마다 number에 누적)
number
split 쓰면 대체하는 것 할 수 있음
s = 'onetwothree'
s.split('two')
['one', ' three']
s1,s2 = s.split ('two')
s = split1 + str(num)+ str(num2......??? (자료 확인)
[Python] 개인 과제 해설 | Notion
[강의자료]
teamsparta.notion.site
'Data Analyst > 과제' 카테고리의 다른 글
| [기초프로젝트 발제] (2) | 2024.11.01 |
|---|---|
| 프로그래밍 기초주차 발제 (1) | 2024.10.14 |
