
rubus0304 님의 블로그
[데이터 전처리 4주차] 강의요약 (H.W_예정) 본문
https://teamsparta.notion.site/Matplotlib-b9098f5265944004b38d8583040ea502
데이터 시각화 (Matplotlib) | Notion
[수업 목표]
teamsparta.notion.site
☑️ Matplotlib.pyplot 에서 plot() 를 활용하는 법을 알아봅시다.
import pandas as pd
import matplotlib.pyplot as plt
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
# 선 그래프 그리기
df.plot(x='A', y='B')
plt.show()
아래처럼 data 안 쓰고 바로 해도 되지만, 나중에 활용을 위해 data 라이브러리로 묶는게 좋

헐 아니네. 제목이랑 , x,y축 값이 안 나온거네? 뭘 잘못 쓴겨 홀리쉿.... 옆에 나오는 콤보상자에서 선택을 해야함..!! 단순히 글자 똑같이 쓰는게 아님 xlabel, ylabel 도 포함되어있나봄. matplotlib.pyplot 즉 plt 에! 선택되면 노란색글씨로 바뀜! 그럼 잘 된거!
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 선 그래프 그리기
plt.plot(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Example Plot')
plt.show()

☑️ 스타일 설정하기
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o')
plt.show()


☑️ 범례 추가하기
#1 label
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
#2 legend
ax.legend(['Data Series'])
#1번 또는 2번 방법으로 범례를 추가할 수 있습니다.
plt.show()
☑️ 축 , 제목 입력하기
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
plt.show()
☑️ 텍스트 추가하기
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
ax.text(3, 3, 'Some Text', fontsize = 12)
ax.text(4, 2, 'Some Text', fontsize = 10)
plt.show()
☑️ 한꺼번에 설정하는 방법 !
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 그래프 그리기
plt.plot(x, y, color='green', linestyle='--', marker='o', label='Data Series')
# 추가 설정
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('Title of the Plot')
plt.legend()
plt.text(3, 8, 'Some Text', fontsize=12) # 특정 좌표에 텍스트 추가
# 그래프 출력
plt.show()
☑️ 너무 작다… → 그래프를 크게 만들어보자!
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6)) # 가로 8인치, 세로 6인치 // # Figure 객체 생성 및 사이즈 설정
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y) # 그래프 그리기
plt.show()
원래 그려놓은 그래프 사이즈를 바꾸려면!
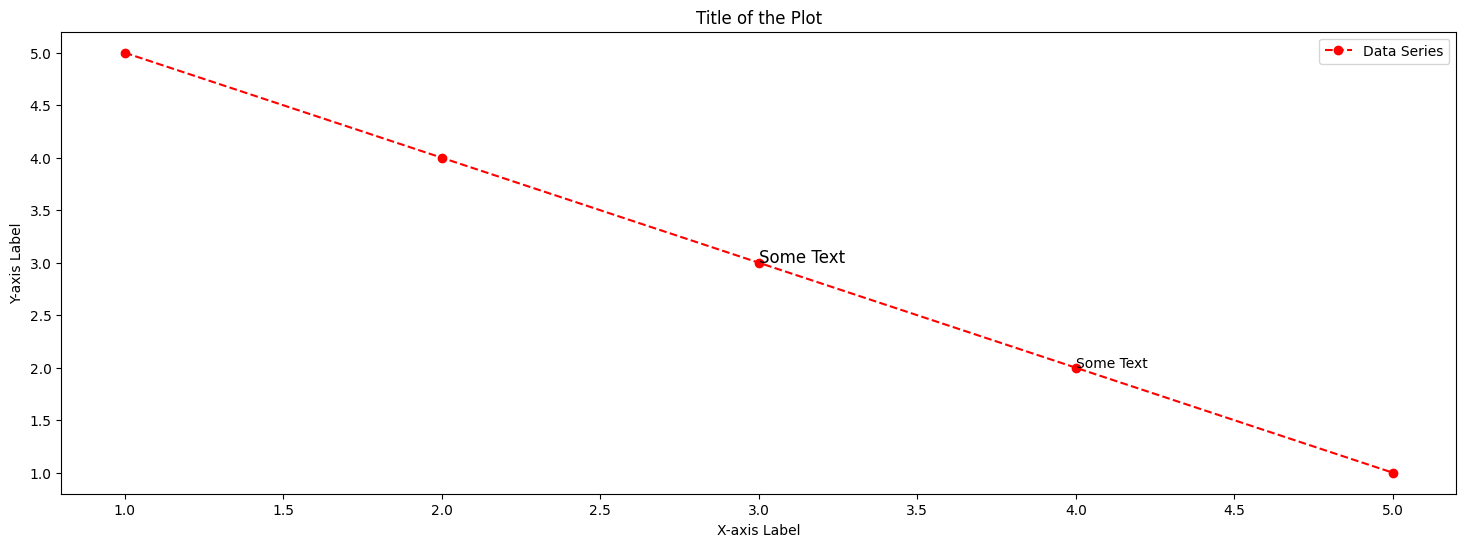
fig, ax = plt.subplots (figsize = (18,6))
ax = df.plot ( x='A', y='B', color = 'red', linestyle = '--', marker = 'o', ax=ax, label = 'Data Series)
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
ax.text(3, 3, 'Some Text', fontsize = 12)
ax.text(4, 2, 'Some Text', fontsize = 10)
plt.show()
그래프 그리기 - 차트
참고) 그래프 자료유형
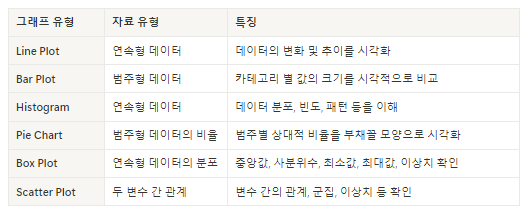
☑️ Line Plot (선 그래프)
import pandas as pd
import matplotlib.pyplot as plt
# 데이터프레임 생성
data = {'날짜': ['2023-01-01', '2023-01-02', '2023-01-03'],
'값': [10, 15, 8]}
df = pd.DataFrame(data)
# '날짜'를 날짜 형식으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
# 선 그래프 작성
plt.plot(df['날짜'], df['값'])
plt.xlabel('날짜')
plt.ylabel('값')
plt.title('선 그래프 예시')
plt.show()
(예시)
1.우선 데이터 불러오기
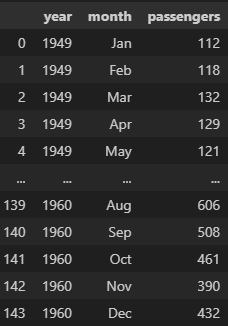
2.데이터 그룹만들기
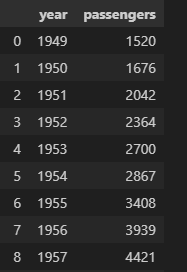
3.데이터그룹을 그래프로 만들어주기
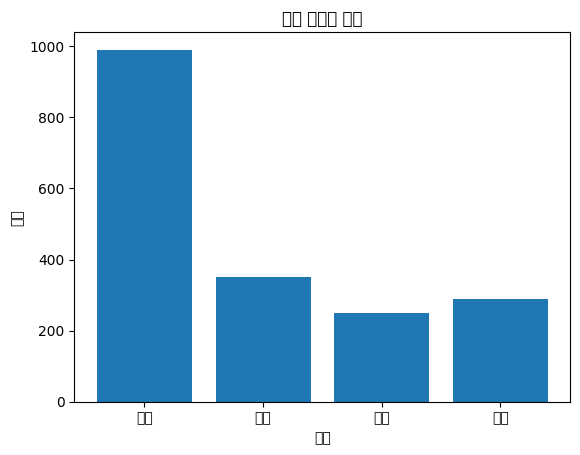
☑️ Bar Plot (막대 그래프)
# 데이터프레임 생성
data = {'도시': ['서울', '부산', '대구', '인천'],
'인구': [990, 350, 250, 290]}
df = pd.DataFrame(data)
# 막대 그래프 작성
plt.bar(df['도시'], df['인구'])
plt.xlabel('도시')
plt.ylabel('인구')
plt.title('막대 그래프 예시')
plt.show()
matplotlib 에서한글 깨짐 문제 해결하기
☑️ Histogram (히스토그램)
- 자료 유형: 연속형 데이터의 분포를 보여줄 때 사용됩니다.
- 활용: 데이터의 빈도나 분포, 패턴을 이해하고자 할 때 유용합니다.
import matplotlib.pyplot as plt
import numpy as np
# 데이터 생성 (랜덤 데이터)
data = np.random.randn(1000)
cf. data.shape
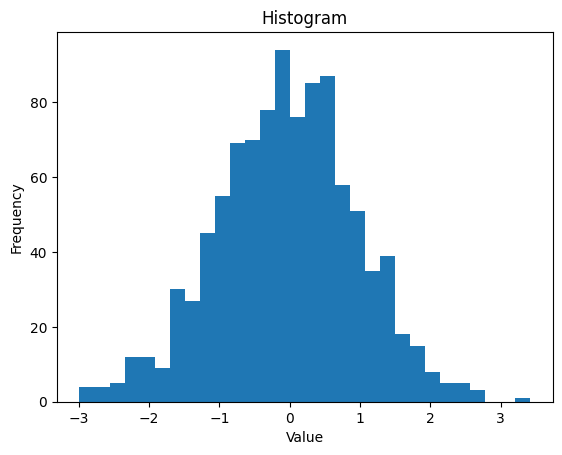
# 히스토그램 그리기
plt.hist(data, bins=30)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Histogram')
plt.show()
☑️ Pie Chart (원 그래프)
- 자료 유형: 범주형 데이터의 상대적 비율을 시각화하는 데 사용됩니다.
- 활용: 전체에 대한 각 범주의 비율을 보여줄 때 유용하며, 주로 비율을 비교하는 데 사용됩니다.
import matplotlib.pyplot as plt
# 데이터 생성
sizes = [30, 20, 25, 15, 10]
labels = ['A', 'B', 'C', 'D', 'E']
# 원 그래프 그리기
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title('Pie Chart')
plt.show()
☑️ Box Plot (박스 플롯)
박스 플롯은 데이터의 분포와 이상치를 시각적으로 보여줍니다.
중앙값, 사분위수, 최솟값, 최댓값 등의 정보를 제공하여 데이터의 통계적 특성을 파악하는 데 사용됩니다.
- 자료 유형: 연속형 데이터의 분포와 이상치를 시각화하는 데 주로 사용됩니다.
- 활용: 데이터의 중앙값, 사분위수(25%, 50%, 75% 위치의 값), 최소값, 최대값, 이상치를 한눈에 파악할 수 있습니다.
import matplotlib.pyplot as plt
import numpy as np
# 데이터 생성
np.random.seed(10)
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
# 박스 플롯 그리기
plt.boxplot(data)
plt.xlabel('Data')
plt.ylabel('Value')
plt.title('Box Plot')
plt.show()
(예시)
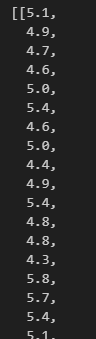
len (list) -> list 값이 총 몇 가지 로 구성되어있는지 여기선 3가지로 구성되있나봄
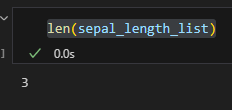
list 옆에 [ ] 로 0,1,2 등 넣어주면 각 list 별로 몇 개씩 들어있는지 알 수 있음 여기선 50개씩 들어있음.
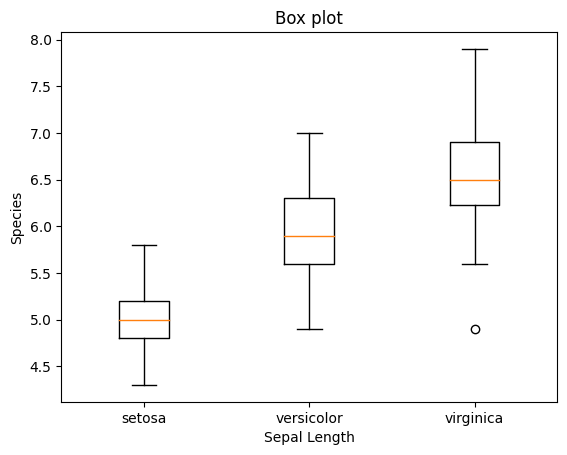
Box plot 상자 (25~75% 구간)
윗 부분 - 75%
노란색 - 중앙 값
아래 부분 - 25%
길게 뻗어 나온 위 - 최대값
길게 뻗어 나온 아래 - 최소값
o - 아웃라이어 최소 최댓값 벗어나있는 값 이므로 보통은 제거하고 만듦.
강의 예시 중 seaborn 예시 에러남. sepal_length 없는데..
훔 에러
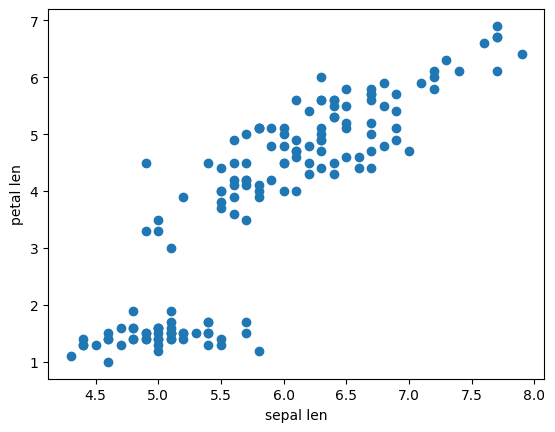
☑️ Scatter Plot (산점도)
- 산점도는 두 변수 간의 관계를 점으로 표시하여 보여주는 그래프입니다.
- 두 변수 간의 상관 관계를 보여주고, 각 점이 데이터 포인트를 나타내며, 그 점들이 어떻게 분포되어 있는지 시각적으로 확인할 수 있습니다.
- 자료 유형: 두 변수 간의 관계 및 상관관계를 보여줄 때 사용됩니다.
- 활용: 변수 간의 관계, 군집, 이상치를 확인하고자 할 때 유용합니다.
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 산점도 그리기
plt.scatter(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Scatter Plot')
plt.show()
(예시)
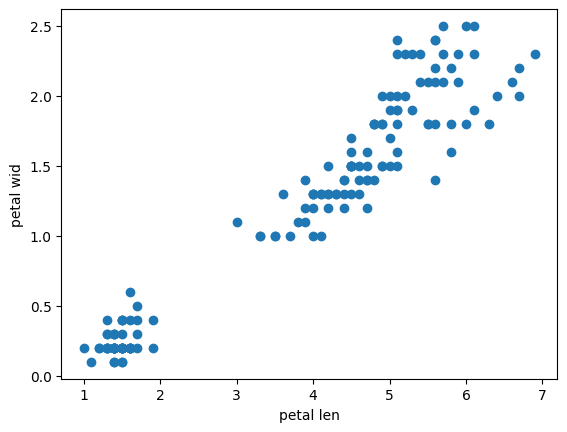
petal -> sepal 로 값을 변경했을 경우
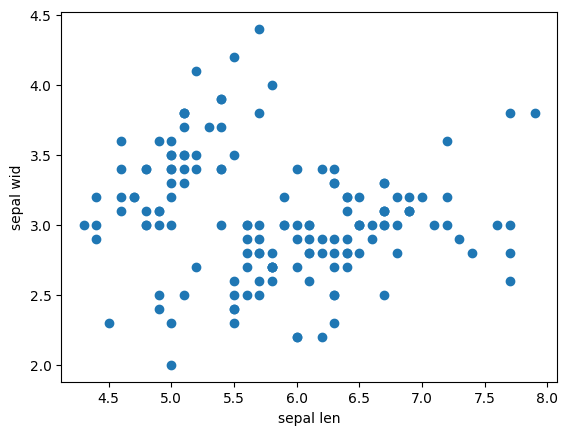
강의에선 에러난다고 했는데.이건 또 왜 나옴 (에러나는 이유는 값 중 string (문자) 값이 들어있어서 그렇다함)
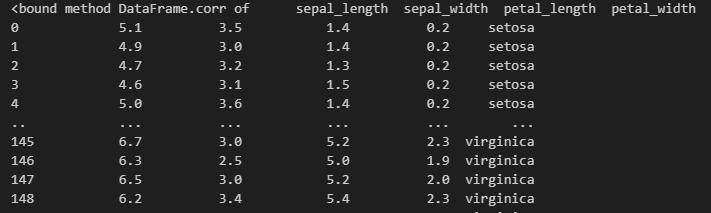
숫자형태의 변수들만 가지고 활용하겠다.
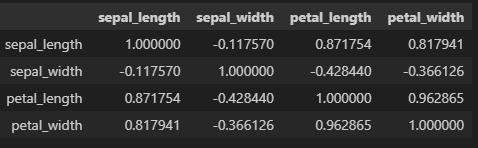
sepal length 와 petal length 관계성
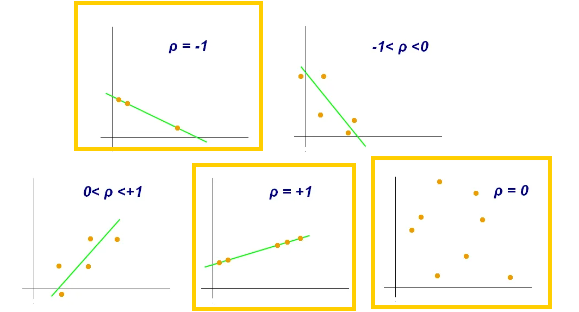
⁉️ 상관관계란?
- 상관관계 확인하기
- 양의 상관관계: 산점도에서 점들이 오른쪽 위 방향으로 일직선으로 분포되어 있을 때를 말합니다. 즉, 하나의 변수가 증가할 때 다른 변수도 증가하는 경향이 있습니다.
- 음의 상관관계: 산점도에서 점들이 왼쪽 위 방향으로 일직선으로 분포되어 있을 때를 말합니다. 하나의 변수가 증가할 때 다른 변수는 감소하는 경향이 있습니다.
- 무상관 관계: 산점도에서 점들이 어떤 방향으로도 일직선으로 분포하지 않고 무작위로 퍼져 있을 때를 말합니다. 즉, 두 변수 간에는 상관관계가 거의 없는 것으로 보입니다.
- 상관관계의 강도 확인하기
- 점들의 모임: 점들이 더 밀집된 곳은 상관관계가 높다는 것을 나타낼 수 있습니다.
- 점들의 방향성: 일직선에 가까운 분포일수록 상관관계가 강할 가능성이 높습니다.
- 상관계수 계산: 피어슨 상관계수와 같은 통계적 방법을 사용하여 상관관계의 정도를 수치적으로 계산할 수 있습니다.
⁉️ 피어슨 상관계수란?
- 피어슨 상관계수(Pearson correlation coefficient)는 두 변수 간의 선형적인 관계를 측정하기 위한 통계적인 방법 중 하나입니다. 주로 연속형 변수들 (숫자값) 간의 상관관계를 평가하는 데 사용됩니다.
- 피어슨 상관계수의 특징:
- 범위: -1에서 1 사이의 값을 가집니다.
- 양의 상관관계: 1에 가까울수록 강한 양의 선형관계를 나타냅니다.
- 음의 상관관계: -1에 가까울수록 강한 음의 선형관계를 나타냅니다.
- 무상관 관계: 0에 가까울수록 선형관계가 거의 없거나 약한 관계를 가집니다.
- ** 다만 양이든 음이든 선형관계는 인과관계와는 별도의 것임. (꼭 x가 증가해서 y가 증가한 것이 인과관계로 볼 수 없음 주의!!!)
3주차 숙제
1) 문제 살펴보기
☑️ flights 데이터셋을 활용해서 그래프를 그려봅시다
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn의 내장 데이터셋 'flights' 불러오기
flights_data = sns.load_dataset('flights')
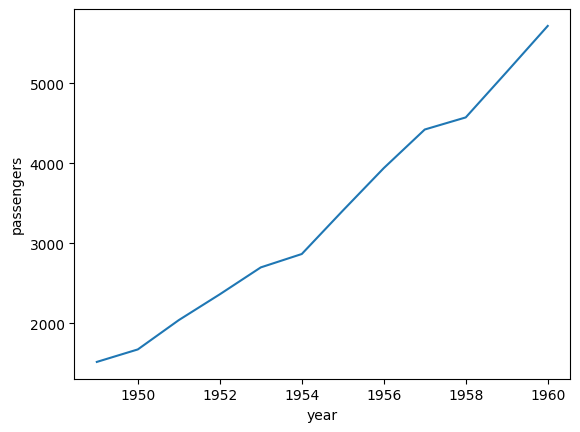
- 연도별 총 승객 수
- 연도별 평균 승객 수
- 승객 수 분포
- 연도별 승객 수와 월간 승객 수
- 월별 승객 수 분포
☑️ tips 데이터셋을 활용해서 그래프를 그려봅시다
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn의 내장 데이터셋 'tips' 불러오기
tips_data = sns.load_dataset('tips')
- 요일별 팁 금액의 평균
- 제목 : Average Tips by Day
- X축 : Day of the Week
- Y축 : Average Tip Amount
- 요일별 총 팁 금액
- 제목 : Total Tips by Day
- X축 : Day of the Week
- Y축 : Total Tip Amount
- 식사 금액 분포
- 제목 : Distribution of Total Bill
- X축 : Total Bill Amount
- Y축 : Frequency
- 식사 금액과 팁 금액의 관계
- 제목 : Tip Amount vs Total Bill
- X축 : Total Bill Amount
- Y축 : Tip Amount
- 요일별 식사 금액 분포
- 제목 : Total Bill Distribution by Day
- X축 : Day of the Week
- Y축 : Total Bill Amount
정답
https://teamsparta.notion.site/Matplotlib-b9098f5265944004b38d8583040ea502
'강의 > 데이터전처리(Pandas)' 카테고리의 다른 글
| [데이터 전처리] 홀로서기 (H.W_예정) (1) | 2024.10.24 |
|---|---|
| [데이터 전처리 3주차] 강의내용 (H.W_예정) (3) | 2024.10.24 |
| [데이터 전처리 1-2주차] 강의요약 (3) | 2024.10.21 |


