

rubus0304 님의 블로그
[QCC 4회차] 본문
[4기] QCC - 4회차
[4기] QCC - 4회차 | Notion
셋팅 안내
teamsparta.notion.site
문제 1 (下)
- 테이블 설명 :
stores 테이블은 각 매장에 대한 정보를 담고 있습니다. 테이블 구조는 다음과 같으며, STORE_NAME, REGION_NAME, SALES, EMPLOYEES, OPEN_DATE, TYPE은 각각 매장 ID, 지역 이름, 매출, 직원 수, 개점일, 매장 유형을 나타냅니다.
컬럼명 타입 설명
| STORE_ID | VARCHAR | 매장 ID (PK) |
| REGION_NAME | VARCHAR | 지역 이름 |
| SALES | NUMERIC | 매출 |
| EMPLOYEES | INT | 직원 수 |
| OPEN_DATE | DATE | 개점일 |
| TYPE | VARCHAR | 매장 유형 |
- 분석해야 할 내용은 다음과 같습니다 :
지역별로 매출이 가장 높은 매장을 조회하는 SQL 문을 작성해주세요. 단, 해당 지역에 매장이 두 개 이상인 경우만 결과에 포함해주세요. 결과는 지역 이름을 기준으로 오름차 정렬해주세요.
출력 값 예시
stores 테이블이 다음과 같다면 :
STORE_ID REGION_NAME SALES EMPLOYEES OPEN_DATE TYPE
| 1 | Seoul | 1000.5 | 10 | 5/1/2020 | Retail |
| 2 | Seoul | 1500.75 | 15 | 3/15/2019 | Retail |
| 3 | Seoul | 100.00 | 5 | 3/12/2020 | Retail |
| 4 | Busan | 2000 | 20 | 6/10/2021 | Wholesale |
| 5 | Daegu | 1200.25 | 12 | 7/30/2018 | Retail |
| 6 | Daegu | 900 | 8 | 9/20/2020 | Retail |
| 7 | Incheon | 500 | 5 | 1/15/2022 | Retail |
- Seoul 지역에는 매장이 3 개 있으며, 매출이 가장 높은 매장은 STORE_ID 2입니다.
- Busan 지역에는 매장이 하나만 있습니다. 따라서 결과에 포함되지 않습니다.
- Daegu 지역에는 매장이 2 개 있으며, 매출이 가장 높은 매장은 STORE_ID 5입니다.
- Incheon 지역에는 매장이 하나만 있습니다. 따라서 결과에 포함되지 않습니다.
정답 (생각보다 단순)
select region_name,
max(sales) highest_sales
from stores
group by 1
having count(distinct store_id) > 1
order by 1;

문제 2 (中)
- 테이블 설명 :
payments 테이블은 사용자의 결제 정보를 포함합니다. 테이블 구조는 다음과 같으며, ID, USER_ID, AMOUNT, PAY_DATE, 그리고 PAYMENT_TYPE은 각각 결제 ID, 사용자 ID, 결제 금액, 결제 날짜, 결제 유형(카드, 현금 등)을 나타냅니다.
컬럼명 타입 설명
| ID | INT | 결제 ID (PK) |
| USER_ID | VARCHAR | 사용자 ID |
| AMOUNT | INT | 결제 금액 |
| PAY_DATE | DATETIME | 결제 날짜 |
| PAYMENT_TYPE | INT | 결제 유형 (0: 현금, 1:카드) |
orders 테이블은 사용자의 상품 배송 정보를 포함합니다. 테이블 구조는 다음과 같으며, ID, USER_ID, ORDER_DATE, 그리고 ITEM은 각각 주문 ID, 사용자 ID, 주문 날짜, 주문한 상품명을 나타냅니다. 해당 테이블의 USER_ID 는 payments 테이블의 USER_ID랑 동일합니다.
- 분석해야 할 내용은 다음과 같습니다 :
최근 특정 사용자들이 결제를 하지 않고 상품을 주문하거나, 결제를 하지 않은 시점에 이미 상품을 주문하는 버그가 발견되었습니다. 🐞 해당 버그를 악용한 사용자를 파악하기 위해 SQL 문을 작성해주세요. 다음 조건에 해당되는 사용자 수를 출력해주세요 :
- 결제를 하지 않고 상품을 주문한 사용자
- 첫 번째 결제일보다 이전에 상품을 주문한 사용자
출력 값 예시
payments 테이블이 다음과 같고 :
ID USER_ID AMOUNT PAY_DATE PAYMENT_TYPE
| 1 | user1 | 3000 | 2023-01-23 10:00:00 | 0 |
| 2 | user3 | 5000 | 2023-01-23 14:00:00 | 1 |
| 3 | user5 | 7000 | 2023-02-23 12:00:00 | 0 |
orders 테이블이 다음과 같다면 :
ID USER_ID ORDER_DATE ITEM
| 1 | user1 | 2023-02-23 09:30:00 | Laptop |
| 2 | user2 | 2023-01-23 15:45:00 | Smartphone |
| 3 | user4 | 2023-01-23 17:20:00 | Headphones |
| 4 | user5 | 2023-01-23 08:00:00 | Monitor |
- user1은 결제 후 상품을 주문했으므로 버그와 무관합니다.
- user2는 결제를 하지 않고 상품을 주문했습니다. 버그를 악용했습니다.
- user4는 결제를 하지 않고 상품을 주문했습니다. 버그를 악용했습니다.
- user5는 첫 번째 결제일 이전에 상품을 주문했습니다. 버그를 악용했습니다.
< 내 답 >
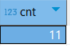
SELECT count(distinct o.USER_ID) cnt
from orders o left join payments p on o.user_id = p.USER_ID
where p.USER_ID is null or o.ORDER_DATE < (select min(pay_date) from payments p2 where p2.user_id=o.user_id)
<정답>
# with 로 first_payment 만들기
with first_payment as(
select user_id, min(pay_date) first_pay_date
from payments
group by 1
)
select o.*, fp.*
from orders o left join first_payment fp on o.USER_ID = fp.user_id
where order_date < first_pay_date
#버그 2
with first_payment as(
select user_id, min(pay_date) first_pay_date
from payments
group by 1
)
select o.*, fp.*
from orders o left join first_payment fp on o.USER_ID = fp.user_id
where order_date < first_pay_date
# 버그 1
with first_payment as(
select user_id, min(pay_date) first_pay_date
from payments
group by 1
)
select o.*, fp.*
from orders o left join first_payment fp on o.USER_ID = fp.user_id
where fp.user_id is null
# 버그 1, 2 합치기
with first_payment as(
select user_id, min(pay_date) first_pay_date
from payments
group by 1
)
select o.*, fp.*
from orders o left join first_payment fp on o.USER_ID = fp.user_id
where fp.user_id is null or order_date < first_pay_date
# 고객 카운트 세기
with first_payment as(
select user_id, min(pay_date) first_pay_date
from payments
group by 1
)
select count(distinct o.USER_ID) cnt
from orders o left join first_payment fp on o.USER_ID = fp.user_id
where fp.user_id is null or order_date < first_pay_date
문제 3 (上)
- 테이블 설명
cart_products 테이블은 쇼핑 카트에서 주문된 아이템에 대한 정보를 담고 있습니다. 테이블 구조는 다음과 같으며, ID, CART_ID, NAME, PRICE는 각각 제품 ID, 주문 번호, 제품 이름, 개별 제품 가격을 나타냅니다.
컬럼명 타입 설명
| ID | INT | 제품 ID |
| CART_ID | INT | 주문 번호 |
| NAME | VARCHAR | 제품 이름 |
| PRICE | INT | 제품 가격 (원 단위) |
- 분석해야 할 내용은 다음과 같습니다 :
데이터 분석팀은 고객이 특정 상품 X를 구매했을 때 상품 Y도 함께 구매할 확률을 분석하고자 합니다. 이를 위해, 쇼핑 카트 데이터에서 서로 다른 두 제품 X와 Y가 같은 주문(CART_ID)에 포함된 주문 수를 확인하려고 합니다.
- 제품 X와 Y가 같은 주문에 포함된 경우를 계산합니다.
- 두 제품은 서로 다른 이름이어야 하며, 한 쌍의 경우(예: Coffee와 Sausages)는 다른 순서(예: Sausages와 Coffee)로도 포함됩니다.
- 결과는 각 제품 쌍과 해당 제품이 함께 포함된 주문 수를 반환해야 합니다.
- 제품 이름 X와 Y를 기준으로 알파벳 순으로 오름차순 정렬합니다.
출력 값 예시
cart_products 테이블이 다음과 같다면 :
ID CART_ID NAME PRICE
| 1 | 1 | Coffee | 3000 |
| 2 | 1 | Sausages | 4000 |
| 3 | 1 | Vegetable | 2000 |
| 4 | 2 | Coffee | 3000 |
| 5 | 2 | Bread | 1500 |
| 6 | 2 | Sausages | 4000 |
| 7 | 3 | Vegetable | 2000 |
| 8 | 3 | Bread | 1500 |
<내 답> butter coffee / coffee butter 값 중복제거
select least(c1.name, c2.name) name_x,
greatest(c1.name, c2.name) name_y,
count(distinct c1.cart_id) orders
from cart_products c1 join cart_products c2 on c1.cart_id = c2.cart_id and c1.name <> c2.name
group by 1,2
order by 1 asc, 2 asc
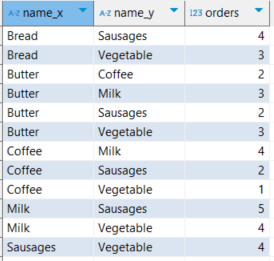
< 정답 > butter coffee / coffee butter 값 중복도 그대로 포함!
Step 1
select c1.cart_id cart_id_x, c1.name cart_name_x,
c2.cart_id cart_id_y, c2.name cart_name_y
from cart_products c1 join cart_products c2 on c1.cart_id = c2.cart_id and c1.name != c2.name
order by 1, 3
Step 2
select c1.name cart_name_x, c2.name cart_name_y, count(distinct c1.cart_id) order_count
from cart_products c1 join cart_products c2 on c1.cart_id = c2.cart_id and c1.name <> c2.name
group by 1, 2
order by 1, 2

'Data Analyst > daily' 카테고리의 다른 글
| [태블로 과제해설] (0) | 2024.12.16 |
|---|---|
| [코트카타 103] (0) | 2024.12.16 |
| 오늘은 새로운 팀 만난 날~ (0) | 2024.12.10 |
| [프로젝트 5주차] (0) | 2024.12.06 |
| [프로젝트 4일차] (1) | 2024.12.04 |

