
rubus0304 님의 블로그
[데이터분석 4주차] Pandas 기본 문법정리 본문
1. 설치, 불러오고, 저장하기
| 문법 | 내용 |
| 기본 설치 | pip install pandas numpy matplotlib terminal 로 pandas 불러오기 Shift + Ctrl + ~ 동시에 누르고 pip install pandas 설치 / pip install seaborn 동일하게 설치 |
| 단축 | Ctrl + Enter 실행 A - above (위) 이동 B - below (아래) 이동 Enter - 입력 Esc - 빠져나오기 dd - delete X - 잘라내기 C - 복사 V - 붙여넣기 |
| Pandas 불러오기 | import pandas as pd import seaborn as sns |
| 데이터 불러오기 | data = sns.load_dataset('tips') -> sns 에서 'tips'라는 데이터셋 가져왔음 data 로 확인! |
| 데이터 저장하기 | data.to_csv("tips_data.csv") "파일명.확장자" |
| 데이터 불러오기 | df = pd.read_csv("tips_data.csv") df |
| 데이터 INDEX Null 값 제거하기 | 1) 저장할 때 Null 값 제거하는 법 index null 값 제거하기 위해 아래처럼 index = False 추가해서 저장할 수 있음! (** read 구문에 넣는 것 아님! data.to_csv 에서 추가해서 저장) (** False 꼭 대문자 주의!! 파이썬 라이브러리에선 저장되어있기 때문에 똑같이 써야함 ) data.to_csv("tips_data.csv") , index=False ) 하고 다시 불러오기 2) 불러올 때 Null 값 제거하는 법 df = pd.read_csv("tips_data.csv", index_col=0) df |
| 파일경로 지정해서 저장하기 | df.to_csv("temp/tips_data.csv", index=False) df = 이 아니고 df. 으로 바로 시작! |
| 엑셀형식으로 저장하기 (확장자 변경) | df.to_excel("temp/tips.data.xlsx", index=False) (에러 참고사항) ** ModuleNotFundError 떴다..! 인터넷 서치를 해보니 비슷한 사례 있었음.. 에러메세지 내 필요모듈 문구대로 터미널에서 openpyxl 설치해봄 오오 혼자서 해결+_+! 엥 근데 열어보니 이상하케 나옴+_+....!!!! 이건 여쭤봐야게따 엑셀은 자기들 프로그램 쓰게하려고 다른 프로그램에서 깨져보이게 하는 경우가 종종 있다고함. 컴퓨터에 저장된 파일로 보면 되고, 혹시 엑셀이 컴터에 안 깔려 있어서 편집이 안 되는 경우, 파이썬에서 csv 파일에서 편집하고 저장하거나, 전체를 변경해야할 경우, 코드 짜서 다시 csv 파일로 이름 바꿔서 저장하면 됨!! 그냥 csv 파일 이름 그대로 하면 덮어씌워져버림 -ㅁ- ㄷㄷㄷ |
2. 인덱스 (Index) / 컬럼
| 문법 | 내용 |
| 인덱스 넣기 | df = pd.DataFram({ 'a' : [1,2,3], 'b' : ['a', 'b', 'c'] }, index = ['idx1', 'idx2', 'idx3']) df 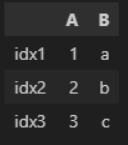 df.loc [ 'idx2' ] - 2번째 행에 대한 정보 가져와라 (근데 열이 행으로 바뀌어서 가져옴) 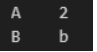 df.sort _index( ) 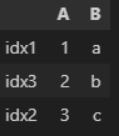 ▼ 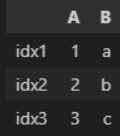 df.set_index ('A') -> index 다시 설정 (A라는 컬럼으로 index 쓰겠다) 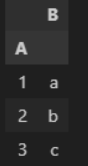 df.index -> index 값 이랑 형식 확인  df.index = [ '1', '2', '3' ] -> index 다시 변경하기 ['ㄱ','ㄴ','ㄷ'] 도 가능..!! df  df.reset_index() -> index를 기존값으로 해주는 것. 0,1,2 기본으로 바뀜 sort( ) 함수로 정렬 시키면 보통 인덱스가 뒤죽박죽 되버리는데, 그 순서로 다시 정렬되어 맨 왼쪽에 index 추가. 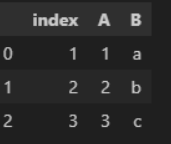 추가적으로, .sort_idex 혹은 .sort_value ('컬럼') 쓰면 해당 '컬럼' 이 row index 로 내려가버림..무조건. 이런 경우에도 reset_index( ) 하면 다시 다른 컬럼들과 동일하게 올라옴. df.reset_index(drop = True) : 기존에 있던 인덱스 없어짐 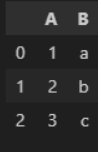 |
| 컬럼 | ** 딕셔너리에서는 = 하면 에러남. 'name' : ['리스트값1',....] 해야함 data= { 'name' : ['Alice', 'Bob', 'Charlie' ], 'age' : ['25, '30', '35'], 'gender' : ['female', 'male', 'male'] } df = pd.DataFrame(data) df 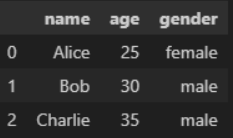 |
| 컬럼 한 개 | df['age'] -> 컬럼 한 개 가져오기  |
| 컬럼들 및 type | df.columns -> 컬럼들 및 type 가져오기 |
| 컬럼 이름 바꾸기 | df.columns = ['이름', '나이', '성별'] -> 컬럼 이름 바꾸기 rename 사용하여 컬럼 이름 바꾸기 (처음엔 df = 로 지정해줘야함) df = df.rename(columns={'이름' : 'name'}) df 여러개 컬럼이름 바꾸기 df.rename(columns={'나이' : 'age', '성별' : '남/여'} ) |
| 컬럼 및 안에 값 추가하기 | df [ '스포츠'] = '축구' df |
| 컬럼 삭제하기 | del df [ '스포츠'] df |
3. 데이터 확인
| 문법 | 내용 |
| 데이터 확인하기 | df = pd.read_csv("temp/tips_data.csv") df |
| .head() | data.head() # head()은 기본 5개 행에 대한 데이터를 보여줌 data.head(3) # ()안에 숫자만큼 데이터를 보여줌 df.head ( ) -> 기본적으로 5개 행 가져옴 (요약, 헤드라인 메소드) df.head(3) -> 만약에 괄호에 숫자넣으면 그 만큼 출력 |
| .info() | data.info() # null 값을 확인할때도 활용 df.info( ) type, null값 여부 등 |
| .describe() | data.describe() # 숫자값에 대해서만 기초통계량 확인이 가능합니다. df.describe( ) -> 몇 개 있는지 (count), 최대, 최소값 등 ** float int (숫자 타입 컬럼값들만 통계 보여줌) |
4. 결측치 확인
| 문법 | 내용 |
| isnull() | # 결측치 확인 : isnull() df.isnull().sum() # 이렇게하면 결측치가 몇개있는지도 알 수 있어요 ! |
| dropna() | # 결측치 제거 : dropna() df.dropna() |
| .duplicated | # 중복 데이터 확인 df.duplicated(subset=['컬럼1', '컬럼2', '컬럼3']) |
| .drop_duplicates | # 중복 데이터 제거 df.drop_duplicates(subset=['컬럼1', '컬럼2', '컬럼3']) |
5.이상치 확인
| 문법 | 내용 |
| 이상치 처리하는 방법# IQR (Interquartile Range) 방법 찾아보기 # 참고 : https://www.scribbr.com/statistics/interquartile-range/ |
|
| # IQR 계산 | # IQR 계산 Q1 = df['컬럼1'].quantile(0.25) Q3 = df['컬럼1'].quantile(0.75) IQR = Q3 - Q1 |
| # 이상치 기준 설정 | # 이상치 기준 설정 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR |
| # 이상치 제거 | # 이상치 제거 df[(df['컬럼1'] >= lower_bound) & (df['컬럼1'] <= upper_bound)] |
| df=pd.DataFrame ({ 'A' : [1,2,3,4], 'B' : [5,6,7,None] }) df df.info() -> null 값이 아닌 값이 몇 개인지 (B에 null 1개 있으므로, B는 3개 정상) df.isna ( ) -> True 면 Null / False 면 정상 df['B'].isna( ) -> B 컬럼만 따로 봤을 떄 df [ df['B'].isna ( ) ] -> Tru/False 값 통해서 일종의 조건식으로 데이터프레임 안에서 불러올 수 있음 / df [ ] 대괄호 안에 조건을 넣어주면, 조건이 True 인 행 전체를 불러오게됨 |
6. 데이터 타입
| 문법 | 내용 |
| astype | astype를 사용한 데이터 타입 변경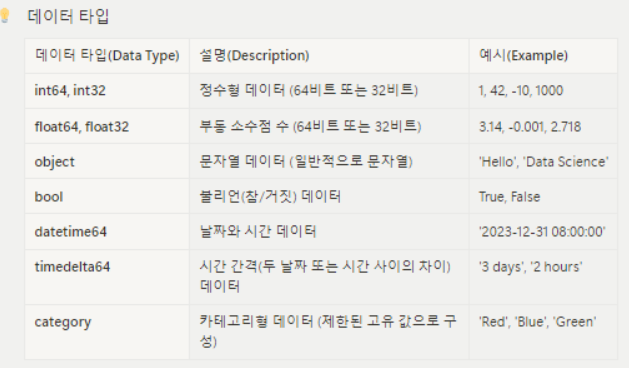 # 데이터 타입 변경을 원한다면 ! df['column_name'].astype(int) df['column_name'].astype(float) df['column_name'].astype(str) df['column_name'].astype(bool) df['column_name'].astype('category') df['column_name'].astype('datetime64[ns]') df['column_name'].astype(complex) df['column_name'].astype(object) .astype( ) 는 Pandas 데이터프레임의 열의 데이터 타입을 변경하는 데 사용됩니다. 이를 사용하여 열의 데이터 타입을 원하는 형식으로 변환할 수 있습니다. DataFrame['column_name'] = DataFrame['column_name'].astype(new_dtype)
import pandas as pd # 예시 데이터프레임 생성 data = {'integer_column': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # 정수형 열을 부동소수점으로 변환 df['integer_column'] = df['integer_column'].astype(float) print(df.dtypes) # 데이터프레임의 열 타입 확인 예시 2) int → str import pandas as pd # 예시 데이터프레임 생성 data = {'numeric_column': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # 숫자열을 문자열로 변환 df['numeric_column'] = df['numeric_column'].astype(str) print(df.dtypes) # 데이터프레임의 열 타입 확인 |
| df['tip'].dtype -> 컬럼 별 데이터 타입 cf. 데이터 타입 int : 정수 ( 1 ) float : 실수 ( 1.0 ) (int와 float 혼합하여 계산시, 결과값은 항상 float 단위가 더 크므로) str : 텍스트 타입 ( '1' ) list : 리스트 타입 ( [1] ) |
|
| 데이터 타입 바꾸기 df [ '컬럼' ] .astype(변경할 타입) df [ 'total_bill' ] = df [ 'total_bill'].astype(str) total_bill 데이터 타입 float (실수) -> object (문자) 소숫점 때문에 문자형식에서는 바로 int (정수) 로 못 바꿈 ( str --x --> int ) float (실수) 형식에선 int 로 변경가능!! str --> float (숫자) -> int |
7.데이터 선택
| 문법 | 내용 |
| lioc | **iloc**은 정수 기반의 인덱스를 사용하고, **loc**은 레이블 기반의 인덱스를 사용 .iloc[로우,컬럼] : 인덱스 번호로 선택 data.iloc[0,2] #행과 열 번호를 통해 특정 데이터를 선택할 수 있음 # iloc을 사용하여 특정 행과 열 선택 selected_data = df.iloc[1:4, 0:2] # 인덱스 1부터 3까지의 행과 0부터 1까지의 열 선택 print(selected_data) iloc [시작: 얼마나: 보폭] 0부터 시작 5개까지, 몇 칸 튈건지 cf. df.iloc[0: :2] 가운데 어디까지 지정 생략하면 처음부터 끝까지 행과 열이 존재하는 경우 컴마로 구분하여 가져옴 df.iloc(행, 열) 몇 행, 몇 열 째 값 가져와 근데 여기서 열 값을 여러개 보고싶다 하면 df.ilo[0, 0:2] 행은 그대로 두고 열 값을 처음부터 2개까지해서 행도 그 열에 맞춘 값 같이 나옴 |
| loc | .loc[로우,컬럼] : 이름으로 선택하기 인덱스가 번호가 아니고 특정 문자일 경우 data.loc['행이름' , '컬럼명'] df.loc['b':, 'A'] b부터 끝까지 행, A 열 *** df.iloc[1:3, 0 ] 일 때, 파이썬 숫자니까 1부터 3이면 0,1,2 번째까지 출력! BUT, loc는 문자니까 정확하게 지정된 그 문자열을 출력!! # 행이름과 컬럼명을 통해서도 특정 데이터를 선택할 수 있음 # loc을 사용하여 특정 행과 열 선택 selected_data = df.loc['b':'d', 'A':'B'] # 레이블 'b'부터 'd'까지의 행과 'A'부터 'B'까지의 열 선택 print(selected_data) |
| 1개의 컬럼 전체를 선택 | data.loc[: , '컬럼명'] #또는 데이터프레임['컬럼명'] 으로도 동일한 값을 선택할 수 있습니다. data['컬럼명'] 여러개의 컬럼을 선택할 경우에도 리스트를 활용해서 선택할 수 있습니다. data[ ['컬럼명1', '컬럼명2', '컬럼명3' ] ] 여러개 컬럼을 선택할때, 내가 원하는 순서대로 데이터를 선택할 수 있습니다. data[ ['컬럼명3', '컬럼명1', '컬럼명2' ] ] |
| 2개 이상의 셀을 선택 | 리스트 형태를 활용해서 데이터를 선택해봅시다. # 2개 컬럼명을 선택할 경우 data.loc[ '행이름' , ['컬럼명1' , '컬럼명2'] ] # 2개 행이름을 선택할 경우 data.loc[ ['행이름1', '행이름2'] , '컬럼명1' ] # 리스트 슬라이싱 : 을 활용해서 특정 범위를 지정하여 선택할 수 있습니다. data.loc[ '행이름' , '컬럼명1' : ] # '컬럼명1' : ==> 컬럼명1부터 끝까지라는 의미 |
| 조건에 따라 데이터를 선택하기 (Boolean Indexing) |
조건에 따라 데이터를 선택하기 (Boolean Indexing) 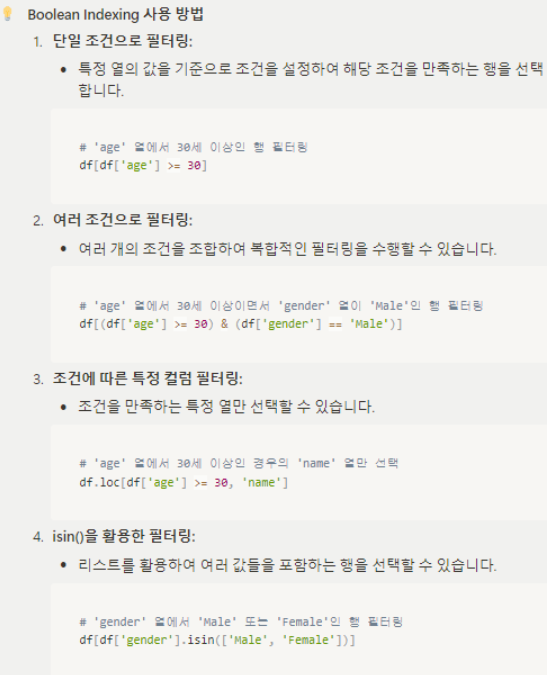 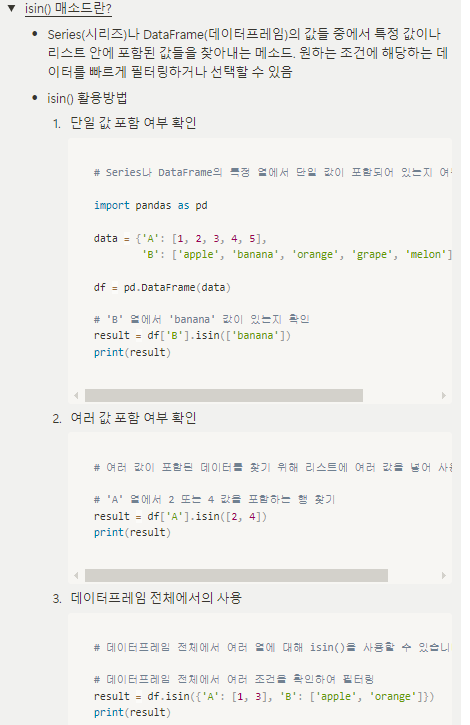 |
| 실습 | 실습해보기 : 특정 조건을 만족하는 데이터를 선택할 경우 비교 연산자를 활용해봅시다. # 예를들어, data['컬럼명1']이 숫자(int)값인 경우 data['컬럼명1'] < 80 # 80보다 작으면 True # 80보다 크면 False 을 반환합니다. 조건을 통해 True/False 로 반환된 값을 활용해서 True에 해당하는 값만 불러올 수 있습니다. condition = data['컬럼명1'] < 80 condition 여러개 조건을 활용해서 값을 불러올 수 있습니다. # 조건1 and 조건2 ==>> 조건1,2 둘다 만족해야한다 True ## and 를 &로 대체해서 사용할 수 있음 condition1 = data['컬럼명1'] < 80 condition2 = data['컬럼명2'] >= 50 condition = condition1 & condition2 data[conditon] # 조건1 or 조건2 ==>> 조건1과 조건2 둘중 하나만 만족하면 True ## or 를 |로 대체해서 사용가능 condition1 = data['컬럼명1'] < 80 condition2 = data['컬럼명2'] >= 50 condition = condition1 | condition2 data[conditon] # ()로 구분해서 조건을 한번에 입력해도 동일하게 활용할 수 있습니다. condition = (data['컬럼명1'] < 80) & (data['컬럼명2'] >= 50) data[conditon] # 이렇게도 가능합니다. data[(data['컬럼명1'] < 80) & (data['컬럼명2'] >= 50)] # 조건이 많아서 행이 길어질 경우, 줄바꿈을 통해 구분해주시면 훨씬 가독성이 올라갑니다. condition = (data['컬럼명1'] < 80) \ & (data['컬럼명2'] >= 50)\ & (data['컬럼명3'] >= 10) data[conditon] |
8. 데이터 추가하기
| 문법 | 내용 |
| df['컬럼명'] = data | df = pd.DataFrame() df['컬럼명'] = data # df라는 데이터프레임에 '컬럼명'이라는 이름의 컬럼이 추가되고,해당 컬럼에 data라는 값이 추가된다. # 이때, data값이 1개의 단일 값인 경우에는 전체 df라는 데이터프레임 행에 data 값이 전체 적용됨 # 즉, # 하나의 값인 경우 => 전체 모두 동일한 값 적용 # (리스트,시리즈)의 형태인 경우 => 각 순서에 맞게 컬럼 값에 적용됨 |
| 신규 컬럼 추가하기 | df = pd.DataFrame() # 컬럼 추가하기 df['EPL'] = 100 df['MLS'] = 60 df['NBA'] = 70 df # 리스트 형태로 컬럼값 추가하기 df['KFC'] = [50, 10, 30] #Tip. 행 수를 맞춰서 입력해줘야함 # 컬럼을 여러 조건 및 계산식을 통해 산출 값으로도 추가가 가능 df['ABC'] = (df['EPL'] + df['NBA']) * df['MLS'] * 2 |
9. 데이터 병합
| 문법 | 내용 |
| concat | 데이터를 위아래로 합치기
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'], 'B': ['B0', 'B1', 'B2']}) df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'], 'B': ['B3', 'B4', 'B5']}) # 위아래로 데이터프레임 연결 result_vertical = pd.concat([df1, df2], axis=0) # 좌우로 데이터프레임 연결 result_horizontal = pd.concat([df1, df2], axis=1) print("위아래 연결 결과:\n", result_vertical) print("\n좌우 연결 결과:\n", result_horizontal) |
| join | |
| merge | 데이터를 좌우로 합치기
|
10. 데이터 집계
| 문법 | 내용 |
| Group by |
# 샘플 데이터프레임 생성 data = { 'Category': ['A', 'B', 'A', 'B', 'A', 'B'], 'Value': [1, 2, 3, 4, 5, 6] } df = pd.DataFrame(data) # 'Category' 열을 기준으로 그룹화하여 'Value'의 연산 수행 grouped = df.groupby('Category').mean() grouped_sum = df.groupby('Category').sum() grouped_count = df.groupby('Category').count() grouped_max = df.groupby('Category').max() grouped_min = df.groupby('Category').min() # 수치형 데이터의 경우에 연산이 가능 - 복수의 열을 기준으로 Group by 함수 사용하기 import pandas as pd # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'A', 'B', 'B', 'A', 'B'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'], 'Value': [1, 2, 3, 4, 5, 6] } df = pd.DataFrame(data) # 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 'Value'의 합 계산 grouped_multiple = df.groupby(['Category', 'SubCategory']).sum() print(grouped_multiple) # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'A', 'B', 'B', 'A', 'B'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'], 'Value1': [1, 2, 3, 4, 5, 6], 'Value2': [10, 20, 30, 40, 50, 60] } df = pd.DataFrame(data) # 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 각 그룹별 'Value1'과 'Value2'의 평균, 합 계산 grouped_multiple = df.groupby(['Category', 'SubCategory']).agg({'Value1': ['mean', 'sum'], 'Value2': 'sum'}) print(grouped_multiple) |
11. 피벗테이블
| 문법 | 내용 |
| 피벗테이블 |
Pivot Table()
# 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'Value': [10, 20, 30, 40, 50] } df = pd.DataFrame(data) # 피벗 테이블 생성: 날짜를 행 인덱스로, 카테고리를 열 인덱스로, 값은 'Value'의 합으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum') print(pivot)
# 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X'], 'Value': [10, 20, 30, 40, 50] } df = pd.DataFrame(data) # 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'와 'SubCategory'를 열 인덱스로, 값은 'Value'의 합으로 집계 pivot = df.pivot_table(index='Date', columns=['Category', 'SubCategory'], values='Value', aggfunc='sum') print(pivot)
# 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'Value1': [10, 20, 30, 40, 50], 'Value2': [100, 200, 300, 400, 500] } df = pd.DataFrame(data) # 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'를 열 인덱스로, 값은 'Value1'과 'Value2'의 평균과 합으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values=['Value1', 'Value2'], aggfunc={'Value1': 'mean', 'Value2': 'sum'}) print(pivot) |
12. 시각화 맛보기
| 문법 | 내용 |
| 시각화 matplotlib |
Group by 나 Pivot Table 함수를 통해 원하는 형태로 데이터를 가공하고 시각화 할 수 있습니 import matplotlib.pyplot as plt import pandas as pd # 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'Value1': [10, 20, 30, 40, 50], 'Value2': [100, 200, 300, 400, 500] } df = pd.DataFrame(data) # 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'를 열 인덱스로, 값은 'Value1'과 'Value2'의 평균으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values=['Value1', 'Value2'], aggfunc='mean') # 피벗 테이블의 선 그래프 시각화 pivot.plot(kind='line') plt.xlabel('Date') plt.ylabel('Values') plt.title('Pivot Table Visualization') plt.legend(title='Category') plt.show() |
13. 데이터 정렬하기
| 문법 | 내용 |
| sort_values('Score') sort_values('Score',ascending=False) sort_index() sort_index(ascending=False) |
# 샘플 데이터프레임 생성 data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], 'Age': [25, 22, 30, 18, 27], 'Score': [85, 90, 75, 80, 95] } df = pd.DataFrame(data) # 정렬 sorted_by_score = df.sort_values('Score') # 'Score' 열을 기준으로 오름차순 정렬 sorted_by_score = df.sort_values('Score',ascending=False) # 'Score' 열을 기준으로 내림차순 정렬 print(sorted_by_score)
# 샘플 데이터프레임 생성 data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], 'Age': [25, 22, 30, 18, 27], 'Score': [85, 90, 75, 80, 95] } df = pd.DataFrame(data) # 정렬 sorted_by_index = df.sort_index() # 인덱스를 기준으로 오름차순 정렬 sorted_by_index = df.sort_index(ascending=False) # 인덱스를 기준으로 내림차순 정렬 print(sorted_by_index) |
| pickle |
|
14. 시각화
| 문법 | 내용 |
| Matplotlib | Matplotlib.pyplot 에서 plot() 를 활용하는 법을 알아봅시다. import pandas as pd import matplotlib.pyplot as plt # 샘플 데이터프레임 생성 data = { 'A': [1, 2, 3, 4, 5], 'B': [5, 4, 3, 2, 1] } df = pd.DataFrame(data) # 선 그래프 그리기 df.plot(x='A', y='B') plt.show() 아래처럼 data 안 쓰고 바로 해도 되지만, 나중에 활용을 위해 data 라이브러리로 묶는게 좋다. 헐 아니네. 제목이랑 , x,y축 값이 안 나온거네? 뭘 잘못 쓴겨 홀리쉿.... 옆에 나오는 콤보상자에서 선택을 해야함..!! 단순히 글자 똑같이 쓰는게 아님 xlabel, ylabel 도 포함되어있나봄. matplotlib.pyplot 즉 plt 에! 선택되면 노란색글씨로 바뀜! 그럼 잘 된거! import matplotlib.pyplot as plt # 데이터 생성 x = [1, 2, 3, 4, 5] y = [2, 4, 6, 8, 10] # 선 그래프 그리기 plt.plot(x, y) plt.xlabel('X-axis') plt.ylabel('Y-axis') plt.title('Example Plot') plt.show() |
| 스타일 설정하기 | 스타일 설정하기 ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o') plt.show()  |
| 범례 추가하기 | 범례 추가하기 #1 label ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series') #2 legend ax.legend(['Data Series']) #1번 또는 2번 방법으로 범례를 추가할 수 있습니다. plt.show() |
| 축 , 제목 입력하기 | 축 , 제목 입력하기 ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series') ax.set_xlabel('X-axis Label') ax.set_ylabel('Y-axis Label') ax.set_title('Title of the Plot') |
| 텍스트 추가하기 | 텍스트 추가하기 ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series') ax.set_xlabel('X-axis Label') ax.set_ylabel('Y-axis Label') ax.set_title('Title of the Plot') ax.text(3, 3, 'Some Text', fontsize = 12) ax.text(4, 2, 'Some Text', fontsize = 10) plt.show() |
| 한꺼번에 설정하는 방법 ! | 한꺼번에 설정하는 방법 ! import matplotlib.pyplot as plt # 데이터 생성 x = [1, 2, 3, 4, 5] y = [2, 4, 6, 8, 10] # 그래프 그리기 plt.plot(x, y, color='green', linestyle='--', marker='o', label='Data Series') # 추가 설정 plt.xlabel('X-axis Label') plt.ylabel('Y-axis Label') plt.title('Title of the Plot') plt.legend() plt.text(3, 8, 'Some Text', fontsize=12) # 특정 좌표에 텍스트 추가 # 그래프 출력 plt.show() |
| 너무 작다… → 그래프를 크게 만들어보자! | 너무 작다… → 그래프를 크게 만들어보자! import matplotlib.pyplot as plt plt.figure(figsize=(8, 6)) # 가로 8인치, 세로 6인치 // # Figure 객체 생성 및 사이즈 설정 x = [1, 2, 3, 4, 5] y = [2, 4, 6, 8, 10] plt.plot(x, y) # 그래프 그리기 plt.show() 원래 그려놓은 그래프 사이즈를 바꾸려면! fig, ax = plt.subplots (figsize = (18,6)) ax = df.plot ( x='A', y='B', color = 'red', linestyle = '--', marker = 'o', ax=ax, label = 'Data Series) ax.set_xlabel('X-axis Label') ax.set_ylabel('Y-axis Label') ax.set_title('Title of the Plot') ax.text(3, 3, 'Some Text', fontsize = 12) ax.text(4, 2, 'Some Text', fontsize = 10) plt.show() |
| 그래프 그리기 - 차트 참고) 그래프 자료유형 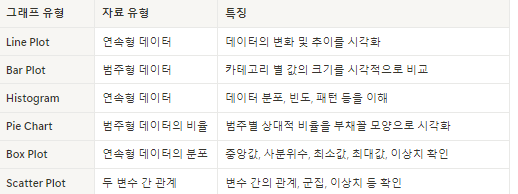 |
|
| Line Plot (선 그래프) import pandas as pd import matplotlib.pyplot as plt # 데이터프레임 생성 data = {'날짜': ['2023-01-01', '2023-01-02', '2023-01-03'], '값': [10, 15, 8]} df = pd.DataFrame(data) # '날짜'를 날짜 형식으로 변환 df['날짜'] = pd.to_datetime(df['날짜']) # 선 그래프 작성 plt.plot(df['날짜'], df['값']) plt.xlabel('날짜') plt.ylabel('값') plt.title('선 그래프 예시') plt.show() (예시) 1.우선 데이터 불러오기 import seaborn as sns
data = sns.load_dataset('flights')
data
2.데이터 그룹만들기 data_grouped = data [['year','passengers']].groupby('year').sum().reset_index()
data_grouped
3.데이터그룹을 그래프로 만들어주기 plt.plot(data_grouped['year'], data_grouped['passengers'])
plt.xlabel('year')
plt.ylabel('passengers')
plt.show
|
|
| Bar Plot (막대 그래프) # 데이터프레임 생성 data = {'도시': ['서울', '부산', '대구', '인천'], '인구': [990, 350, 250, 290]} df = pd.DataFrame(data) # 막대 그래프 작성 plt.bar(df['도시'], df['인구']) plt.xlabel('도시') plt.ylabel('인구') plt.title('막대 그래프 예시') plt.show() matplotlib 에서한글 깨짐 문제 해결하기 |
|
Histogram (히스토그램)
import matplotlib.pyplot as plt import numpy as np # 데이터 생성 (랜덤 데이터) data = np.random.randn(1000) cf. data.shape # 히스토그램 그리기 plt.hist(data, bins=30) plt.xlabel('Value') plt.ylabel('Frequency') plt.title('Histogram') plt.show() |
|
Pie Chart (원 그래프)
# 데이터 생성 sizes = [30, 20, 25, 15, 10] labels = ['A', 'B', 'C', 'D', 'E'] # 원 그래프 그리기 plt.pie(sizes, labels=labels, autopct='%1.1f%%') plt.title('Pie Chart') plt.show() |
|
| Box Plot (박스 플롯) 박스 플롯은 데이터의 분포와 이상치를 시각적으로 보여줍니다. 중앙값, 사분위수, 최솟값, 최댓값 등의 정보를 제공하여 데이터의 통계적 특성을 파악하는 데 사용됩니다.
import numpy as np # 데이터 생성 np.random.seed(10) data = [np.random.normal(0, std, 100) for std in range(1, 4)] # 박스 플롯 그리기 plt.boxplot(data) plt.xlabel('Data') plt.ylabel('Value') plt.title('Box Plot') plt.show() (예시) iris = sns.load_dataset("iris")
iris
species = iris['species'].unique()
sepal_length_list = [iris[iris['species'] == s] ['sepal_length'].tolist() for s in iris['species'].unique()]
sepal_length_list
len (list) -> list 값이 총 몇 가지 로 구성되어있는지 여기선 3가지로 구성되있나봄 len(sepal_length_list)
list 옆에 [ ] 로 0,1,2 등 넣어주면 각 list 별로 몇 개씩 들어있는지 알 수 있음 여기선 50개씩 들어있음. len(sepal_length_list[0])
plt.boxplot(sepal_length_list, labels=species)
plt.xlabel('Sepal Length')
plt.ylabel('Species')
plt.title('Box plot')
plt.show()
Box plot 상자 (25~75% 구간) 윗 부분 - 75% 노란색 - 중앙 값 아래 부분 - 25% 길게 뻗어 나온 위 - 최대값 길게 뻗어 나온 아래 - 최소값 o - 아웃라이어 최소 최댓값 벗어나있는 값 이므로 보통은 제거하고 만듦. 강의 예시 중 seaborn 예시 에러남. sepal_length 없는데.. sns.boxplot(x='species', y='sepal_length_list', data=iris)
plt.show()
훔 에러 |
|
Scatter Plot (산점도)
# 데이터 생성 x = [1, 2, 3, 4, 5] y = [2, 3, 5, 7, 11] # 산점도 그리기 plt.scatter(x, y) plt.xlabel('X-axis') plt.ylabel('Y-axis') plt.title('Scatter Plot') plt.show() (예시) plt.scatter(iris['petal_length'], iris['petal_width'])
plt.xlabel('petal len')
plt.ylabel('petal wid')
plt.show()
petal -> sepal 로 값을 변경했을 경우 plt.scatter(iris['sepal_length'], iris['sepal_width'])
plt.xlabel('sepal len')
plt.ylabel('sepal wid')
plt.show()
강의에선 에러난다고 했는데.이건 또 왜 나옴 (에러나는 이유는 값 중 string (문자) 값이 들어있어서 그렇다함) iris.corr
숫자형태의 변수들만 가지고 활용하겠다. iris.corr(numeric_only=True)
sepal length 와 petal length 관계성 plt.scatter(iris['sepal_length'], iris['petal_length'])
plt.xlabel('sepal len')
plt.ylabel('petal len')
plt.show()
|
|
⁉️ 상관관계란?
⁉️ 피어슨 상관계수란?
|
|
'Data Analyst > Weekly' 카테고리의 다른 글
| [프로젝트] 2주차 (0) | 2025.01.17 |
|---|---|
| [WIL] 프로젝트 아이디어 (2) | 2025.01.03 |
| [데이터분석 3주차] 관심 데이터직무 넓히기 & 파이썬 문법복습 (0) | 2024.10.20 |
| [데이터분석 2주차] 데이터분석 도메인 이해, 파이썬 기초문법 (2) | 2024.10.12 |
| Python 강의요약 (4) | 2024.10.08 |
'Data Analyst/Weekly' Related Articles
more
