
rubus0304 님의 블로그
[통계야 놀자 4회차] 회귀분석 본문
그렇다면 만약 게임시간이 1000시간이면, 전기세는 얼마일까요?
우리가 가진 데이터셋에 해당 값이 없을 때, 이를 예측하기 위해 ‘회귀분석’의 개념이 도입됩
니다. 이러한 예측을 위해 위 그래프에서 붉은색으로 보이는 ‘추세선’ 이 필요한데요!
회귀분석의 목적은 이 ‘추세선’을 찾는 것이 목적이 됩니다.
추세선 = “우리가 이미 가지고 있는 데이터들을 가장 잘 설명해주는 선” 을 의미합니다.
추세선은 y = a+bx (방정식)으로 표현됩니다.
x: 게임시간(독립변수) y: 전기세(종속변수) a: 절편(x 가 0일때 y값) b: 기울기
이렇게 추세선을 파악함으로써, 게임시간이 1000시간과 추세선이 만나는 점을 통해 종속변수를
예측할 수 있게 되는 것입니다. 이러한 특징을 통해, 데이터분석에서는 예측을 진행할 때 회귀분
석을 주로 수행합니다. 😊

회귀분석의 특징, 종류
정합성 검증 & 결과 해석
→ 결정계수 R_squared(R²) 를 확인합니다.
결정계수는 종속변수와 독립변수의 관계를 나타내는 수치입니다.
결정계수 해석을 위해 회귀식이 도출되는 과정을 확인해 보겠습니다.
기울기가 0, y절편이 y의 평균인 선을 통해, 엉망인 회귀선을 그릴 수 있습니다.
그림에서 점선으로 표시된 부분이 되겠습니다.
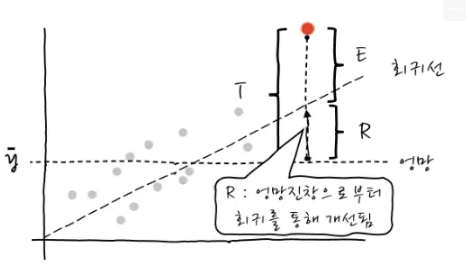

R2: (결정계수) 얼마나 돌아갔는가 (회귀식이 얼마나 설명력을 갖는지. 얼마나 정확한거야)
- ( 전체 오류 중에 얼마나 보완할 수 있어? )
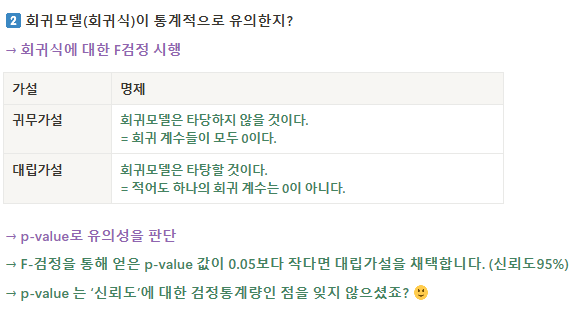
- ( 보완할 수 있는 걸 알겠는데 통계적으로 이거 써도되는지 검정! )
* F- 검정
집단 개수 : 주로 3개 이상
- 두 개 이상의 그룹의 분산 비교
- 3개 이상의 집단 간 평균의 차이 비교
- 회귀식 검정
검정통계량 보다 P-value 가 중요 (P-value를 통해 유의성 판단할 수 있음. 통상적으로 신뢰도 95%)
→ p-value로 유의성을 판단
→ F-검정을 통해 얻은 p-value 값이 0.05보다 작다면 대립가설을 채택합니다. (신뢰도95%)
→ p-value 는 ‘신뢰도’에 대한 검정통계량
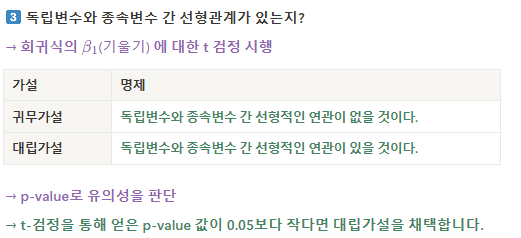
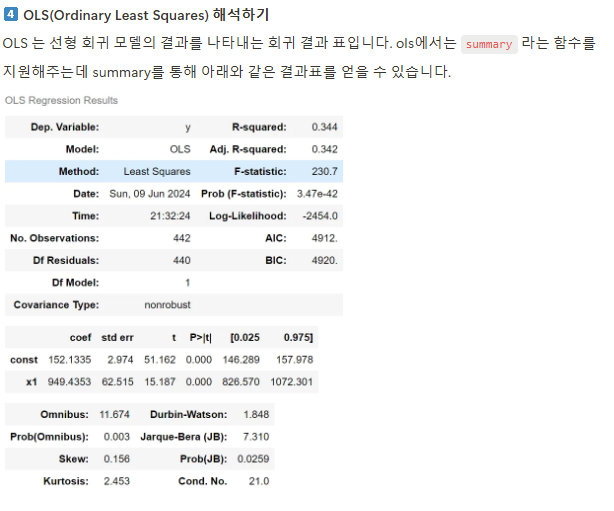
전체 해석은 아래와 같습니다. 주요 지표는 파란 글씨를 참고해주세요!
- Dep. Variable (y): 종속 변수, 즉 회귀분석에서 설명하고자 하는 변수입니다.
- R-squared (0.344): 결정계수로, 회귀 모델이 종속 변수의 변동성을 얼마나 설명하는지를 나타냅니다. 이 값은 0에서 1 사이에 위치하며, 0.344는 약 34.4%의 변동성이 설명된다는 것을 의미합니다.
- Adj. R-squared (0.342): 수정된 결정계수로, 설명 변수의 개수를 고려하여 R-squared 값을 조정한 것입니다. 변수의 수가 늘어날 때 발생하는 과적합을 방지하기 위해 사용됩니다. 0.342는 모델이 적절하게 조정되었음을 나타냅니다.
- Method (Least Squares): 사용된 회귀 방법이 최소제곱법임을 나타냅니다.
- 최소제곱법: 근사적으로 구하려는 해와 실제 해의 오차의 제곱의 합이 최소가 되는 해를 구하는 방법
- F-statistic (230.7): 회귀 모형의 전체 유의성을 검정하는 F-통계량입니다. 값이 클수록 모형이 유의미할 가능성이 높습니다. ( 0 부터 무한대까지)
- Prob (F-statistic) (3.47e-42): F-통계량의 p-값으로, 이 값이 매우 작으면 (예: 0.05 이하) 대립가설을 채택할 수 있습니다. 이 경우 p-값이 거의 0에 가까우므로, 회귀 모형이 통계적으로 유의미하다고 볼 수 있습니다.
- Log-Likelihood (-2454.0): 회귀 모형의 로그 우도(likelihood)입니다. 값이 클수록 모형이 데이터에 더 잘 맞는다는 것을 의미합니다.
- No. Observations (442): 사용된 관측치(데이터 포인트)의 수입니다.
- Df Residuals (440): 잔차의 자유도, 즉 전체 데이터 포인트 수에서 회귀 계수의 수를 뺀 값입니다.
- Df Model (1): 모델에 포함된 설명 변수의 수입니다.
- Covariance Type (nonrobust): 공분산 추정의 유형을 나타냅니다. nonrobust는 기본 공분산 추정이 사용되었음을 의미합니다.
- coef (coefficients):
- const (152.1335): 상수항(절편)으로, 독립변수가 0일 때 종속 변수의 예측값입니다.
- x1 (949.4353): 설명 변수 x1의 회귀 계수로, 독립변수가 1 단위 증가할 때 종속 변수가 평균적으로 949.4353 단위 증가한다는 의미입니다.
- std err (Standard Error): 회귀 계수 추정치의 표준 오차입니다. 상수항과 x1에 각각 2.974, 62.515가 있습니다.
- t (t-statistic): 회귀 계수가 0인지 검정하는 t-값입니다. 절대값이 클수록 해당 계수가 유의미할 가능성이 높습니다. x1의 t-값은 15.187로 매우 크며 유의미함을 나타냅니다.
- P>|t| (P-value): 각 계수에 대한 p-값입니다. 일반적으로 0.05보다 작으면 해당 계수는 유의미하다고 판단됩니다. x1과 상수항의 p-값은 모두 0으로, 매우 유의미합니다.
- [0.025 0.975] (Confidence Interval): 회귀 계수에 대한 95% 신뢰구간입니다. 예를 들어, x1의 신뢰구간은 [826.570, 1072.301]로, 이 범위 내에서 실제 계수가 있을 가능성이 95%입니다.
- Omnibus (11.674): 잔차의 정규성을 검정하는 Omnibus 검정 통계량입니다. 값이 작을수록 잔차가 정규분포에 가깝다는 의미입니다.
- Prob(Omnibus) (0.003): Omnibus 검정의 p-값입니다. 0.05보다 작으므로 잔차가 정규분포에서 벗어날 가능성이 있습니다.
- Skew (0.156): 잔차의 왜도(skewness)입니다. 값이 0에 가까울수록 대칭적입니다.
- Kurtosis (2.453): 잔차의 첨도(kurtosis)입니다. 3에 가까울수록 정규분포에 가깝습니다. 2.453은 정규분포보다 조금 더 평평함을 의미합니다.
- Durbin-Watson (1.848): 잔차의 자기상관을 검정하는 통계량입니다. 2에 가까우면 자기상관이 없음을 의미합니다.
- Jarque-Bera (JB) (7.310): 잔차의 정규성을 검정하는 Jarque-Bera 검정 통계량입니다.
- Prob(JB) (0.0259): Jarque-Bera 검정의 p-값입니다. 0.05보다 작아 잔차가 정규성을 만족하지 않을 가능성이 있습니다.
- Cond. No. (21.0): 설명 변수의 다중공선성을 나타내는 조건수입니다. 값이 높으면 다중공선성 문제가 있음을 시사합니다.
(통용)
[ 금일수업 요약 ]
- 우리는 오늘 데이터분석 기법 중 ‘회귀분석’을 학습했습니다.
- 회귀분석은 독립변수와 종속변수가 나누어진(또는 나눌 수 있는)데이터를 기반으로 진행됩니다.
- 독립변수는 원인, 종속변수는 결과입니다.
- 귀무가설과 대립가설의 의미는 아래와 같습니다.
- 귀무가설은 차이가 없거나 의미 있는 차이가 없는 경우의 가설입니다.
- 대립가설은 차이가 있는 경우의 가설입니다.
- 회귀분석은 크게 3단계로 진행됩니다.
- 독립변수, 종속변수 설정
- 데이터 경향성 확인
- 정합성 검증 & 결과 해석
- 회귀분석의 결과해석을 위해, 아래 세가지 검증이 필요합니다.
- 회귀식이 얼마나 설명력을 가지는지
- 회귀식이 통계적으로 유의한지
- 독립변수와 종속변수 간 상관관계가 유의미한지
- 각각의 검정통계량(t-value, F-value)이 가지는 숫자의 의미보다, 이를 신뢰할 수 있는지(p-value)에 포커스를 맞춰주시면 됩니다.
[파이썬 공부하는 방법]
라이브세션 과제용 데이터셋 3개 있음. (SQl 파이썬, 개인과제용) 한 줄이면 결과 나오니까.
- 그걸로 예측 하는 것 연습
- 원하는 데이터 추출하고 계속 다른 데이터셋 가지고 나만의 방식으로 계속 핸들링하는 연습.
'Data Analyst > 라이브세션' 카테고리의 다른 글
| [통계야 놀자] 강의 주요내용 (1) | 2024.11.21 |
|---|---|
| [통계야 놀자] 회귀와 예측 - 실습 (0) | 2024.11.20 |
| [통계야 놀자 3회차] 복습 & 실습 (1) | 2024.11.18 |
| [통계 라이브세션2] 주요 강의내용 정리 (1) | 2024.11.14 |
| [라이브세션 6주차] 강의정리 (0) | 2024.10.31 |


