
rubus0304 님의 블로그
[기초] 분류분석 - 로지스틱회귀 본문
https://teamsparta.notion.site/08d443adff404876b5dde2dc9ca57c63
머신러닝의 이해와 라이브러리 활용 기초 | Notion
실습 정답 자료
teamsparta.notion.site
https://teamsparta.notion.site/3-fe9d135d7f3441ab97bd71a4c224391c
3. 분류분석 - 로지스틱회귀 | Notion
1. 학습목표
teamsparta.notion.site
https://www.kaggle.com/c/titanic/data
Titanic | Novice
Kaggle profile for Titanic
www.kaggle.com

pandas.pydata.org
반드시 괄호 2개 넣어야 에러 안 남.
평가지표 도 회귀에서처럼 metrics 안에 있음
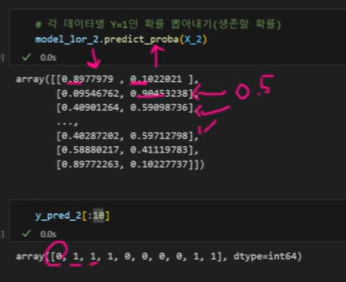
죽을 확율 0.09, 살 확율 0.9 -> 1 (살 확률이 높을 때)
sklearn 버전 확인하기
회사입사하면 버전관리 꼭 확인하기 (sklearn 사이트에서)
- 로지스틱회귀
- 장점: 역시 직관적이며 이해하기 쉽다.
- 단점: 복잡한 비선형 관계를 모델링 하기 어려울 수 있음
- Python 패키지
- sklearn.linear_model.LogisticRegresson
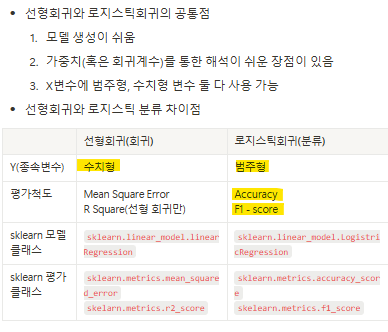
선형회귀(회귀)
|
Y(종속변수)
|
수치형
|
범주형
|
|
평가척도
|
Mean Square Error R Square(선형 회귀만)
|
Accuracy F1 - score
|
|
sklearn 모델 클래스
|
sklearn.linear_model.linearRegression
|
sklearn.linear_model.LogistricRegression
|
|
sklearn 평가 클래스
|
sklearn.metrics.mean_squared_error skelarn.metrics.r2_score
|
sklearn.metrics.accuracy_score skelearn.metrics.f1_score
|
숫자를 예측하는 회귀분석, 범주를 맞추는 분류분석에 대해서 배워보았어요.
그럼 이제 세상에 있는 모든 문제를 다 해결해 볼 수 있을까요?
대답은 No. 실제로 데이터의 모델링은 데이터 사이언스 업무의 아주 일부분이며, 대부분 데이터의 수집과 전처리에 아주 많은 시간을 쏟게 된답니다
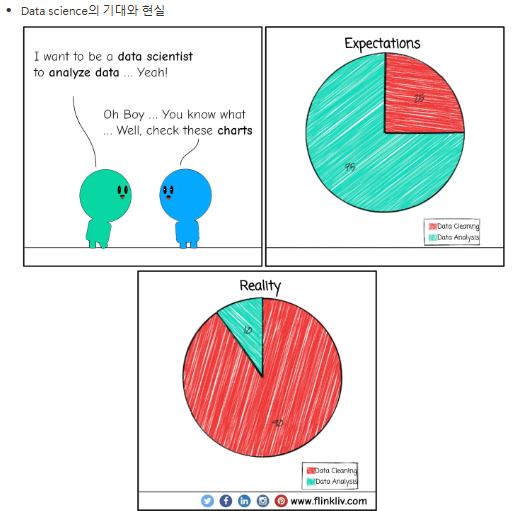
Data cleansing 이슈가 제일 큼
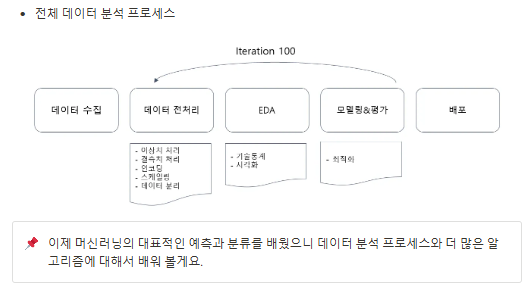
숫자 선형회귀, 범주 로지스틱 회귀 까지 배움
전처리에 대해 더 배울 예정~~
'강의 > 머신러닝' 카테고리의 다른 글
| [머신러닝 심화 2주차] (0) | 2024.11.27 |
|---|---|
| [머신러닝 심화 1주차] (0) | 2024.11.27 |
| [기초] 3.선형회귀 심화 (0) | 2024.11.19 |
| [기초] 2.회귀분석 - 선형회귀 (0) | 2024.11.18 |
| [기초] 1. 머신러닝의 기초 (2) | 2024.11.18 |

