https://teamsparta.notion.site/1-8048e291815143c3bfc90b5848e8dff0
y축은 값 데이터라 따로 안 넣어도 됨
범주형
x축 수치 또는 범주, y;는 수치형
전체의 50% 참고로 평균은 없음
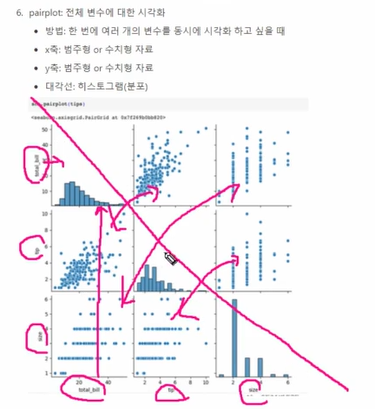
histogram: 수치형 자료 빈도 시각화
방법: 연속형 분포를 나타내고 싶을 때, 데이터가 몰려있는 구간을 파악하기 쉬움
x축: 수치형 자료
y축: 자료의 빈도수
bins 로 보여주는 값 정할 수 있음
bullian indexing 추가
fillna (value) -> value 자리에 평균, 중앙, 최빈값 넣을 수 있음
isna ( ) 는 비어있는 값
notta ( ) 비어있지 않은 값
☑️ 범주형 데이터 전처리 - 인코딩(Encoding)
인코딩 : 어떤 정보를 정해진 규칙에 따라 변환하는 것 (범주형 자료에 대한 전처리 )
우리가 만든 머신러닝 모델은 숫자를 기반으로 학습하기 때문에 반드시 인코딩 과정이 필요
☑️ 수치형 데이터 전처리 - 스케일링(Scaling)
인코딩 이 범주형 자료에 대한 전처리 라고 한다면, 스케일링 은 수치형 자료에 대한 전처리 입니다.
머신러닝의 학습에 사용되는 데이터들은 서로 단위 값이 다르기 때문에 이를 보정한다고 생각해주세요.
2.5 데이터 분리
☑️ 과적합은 머신러닝의 적
쉬운 예시)
수능을 준비하는 고3 학생이라고 생각합시다. 수능을 준비하기 위해서 고3 3월 모의고사만 열심히 공부를 하고 수능을 보러가면 어떻게 될까요? 3월 모의고사는 고3의 수업 과정을 포함하지 않기 때문에 수능에서 좋은 점수를 받긴 어렵겠죠.
이와 같이 국소적인 문제를 해결하는 것에 집중한 나머지 일반적인 문제를 해결하지 못하는 현상 을 과대적합 이슈라 합니다.
즉, 과대적합(Overfitting) 이란 데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상 을 말합니다. 다음 예시를 볼게요!
(실습) 데이터 전체 프로세스적용
데이터 로드 & 분리
탐색적 데이터 분석(EDA)
데이터 전처리
결측치 처리
수치형: Age
범주형: Embarked
삭제 : Cabin, Name
전처리
수치형: Age, Fare, Sibsp+Parch
범주형
레이블 인코딩: Pclass, Sex
원- 핫 인코딩: Embarked
모델 수립
평가
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split ( titaninc_df [[ 'Fare' , 'Sex' ]], titaninc_df [[ 'Survived' ]],
test_size = 0.3 , shuffle = True , random_state = 42 , stratify = titaninc_df [[ 'Survived' ]])
print ( X_train .shape, X_test .shape, y_train .shape, y_test .shape)
-
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib . pyplot as plt
train_df = pd . read_csv ( "C:/Users/82106/Desktop/데이터분석/강의/6.파이썬/4.머신러닝/ML/titanic/train.csv" )
test_df = pd . read_csv ( "C:/Users/82106/Desktop/데이터분석/강의/6.파이썬/4.머신러닝/ML/titanic/test.csv" )
train_df . describe ( include = 'all' )
all ?
#기초가공: Family 변수생성
train_df_2 = train_df . copy ()
def get_family ( df ):
df [ 'Family' ] = df [ 'SibSp' ] + df [ 'Parch' ] + 1
return df
get_family ( train_df_2 ). head ( 3 )
+1 ?
# 숫자형 변수들의 이상치를 확인하기 위하여 pairplot
sns . pairplot ( train_df_2 [[ 'Age' , 'Fare' , 'Family' ]])
train_df_2 = train_df_2 [ train_df_2 [ 'Fare' ] < 512 ]
train_df_2 [[ 'Fare' ]]. describe ()
[결측치 처리]
# 결측치처리
def get_non_missing ( df ):
Age_mean = train_df_2 [ 'Age' ]. mean ()
Fare_mean = train_df_2 [ 'Fare' ]. mean ()
df [ 'Age' ] = df [ 'Age' ].fillna( Age_mean )
#train 데이터에는 필요하지않으나 test데이터에 결측치 존재해서 추가
df [ 'Fare' ] = df [ 'Fare' ].fillna( Fare_mean )
df [ 'Embarked' ] = df [ 'Embarked' ].fillna( 'S' )
return df
get_non_missing ( train_df_2 ). info ()
[수치형]
def get_numeric_sc ( df ):
# sd_sc: Fare , mm_sc : Age, Family
from sklearn . preprocessing import StandardScaler , MinMaxScaler
sd_sc = StandardScaler ()
mm_sc = MinMaxScaler ()
sd_sc . fit ( train_df_2 [[ 'Fare' ]])
df [ 'Fare_sd_sc' ] = sd_sc . transform ( df [[ 'Fare' ]])
mm_sc . fit ( train_df_2 [[ 'Age' , 'Family' ]])
df [[ 'Age_mm_sc' , 'Family_mm_sc' ]] = mm_sc . transform ( df [[ 'Age' , 'Family' ]])
return df
get_numeric_sc ( train_df_2 ). describe ()
[범주형]
1) 원-핫 인코딩
def get_category ( df ):
from sklearn . preprocessing import LabelEncoder , OneHotEncoder
le = LabelEncoder ()
le2 = LabelEncoder ()
oe = OneHotEncoder ()
le . fit ( train_df_2 [[ 'Pclass' ]])
df [ 'Pclass_le' ] = le . transform ( df [ 'Pclass' ])
le2 . fit ( train_df_2 [[ 'Sex' ]])
df [ 'Sex_le' ] = le2 . transform ( df [ 'Sex' ])
#index reset을 하기위한 구문
df = df .reset_index()
oe . fit ( train_df_2 [[ 'Embarked' ]])
embarked_csr = oe . transform ( df [[ 'Embarked' ]])
embarked_csr_df = pd . DataFrame ( embarked_csr . toarray (), columns = oe . get_feature_names_out ())
df = pd . concat ([ df , embarked_csr_df ], axis = 1 )
return df
train_df_2 = get_category ( train_df_2 )
[모델 만들기]
def get_model ( df ):
from sklearn . linear_model import LogisticRegression
model_lor = LogisticRegression ()
X = df [[ 'Age_mm_sc' , 'Fare_sd_sc' , 'Family_mm_sc' , 'Pclass_le' , 'Sex_le' , 'Embarked_C' , 'Embarked_C' , 'Embarked_C' ]]
y = df [[ 'Survived' ]]
return model_lor . fit ( X , y )
model_output = get_model ( train_df_2 )
model_output
[평가]
X = train_df_2 [[ 'Age_mm_sc' , 'Fare_sd_sc' , 'Family_mm_sc' , 'Pclass_le' , 'Sex_le' , 'Embarked_C' , 'Embarked_C' , 'Embarked_C' ]]
y_pred = model_output . predict ( X )
#평가
from sklearn . metrics import accuracy_score , f1_score
print ( accuracy_score ( train_df_2 [ 'Survived' ], y_pred ))
print ( f1_score ( train_df_2 [ 'Survived' ], y_pred ))
[Test 데이터로 적용하기 ]
test_df_2 = get_family ( test_df )
test_df_2 = get_non_missing ( test_df_2 )
test_df_2 = get_numeric_sc ( test_df_2 )
test_df_2 = get_category ( test_df_2 )
type ( model_output )
확인하면서 test_dt_2 에 계속 엎어씌우기
model_output . classes_
model_output . coef_
model_output . intercept_
교차 검증과 GridSearch
☑️ 교차 검증(Cross Validation)
위에서 모델을 평가하기 위한 별도의 테스트 데이터로 평가하는 과정을 알아보았어요. 하지만 이때도, 고정된 테스트 데이터가 존재하기 때문에 과적합을 취약한 단점이 있답니다. 이를 피하기 위해서 교차검증 방법 에 대해서 알아보아요.
교차검증 (Cross Validation)데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용 하는 방법
(실습)
1) K-fold 수행하기
from sklearn . model_selection import KFold
import numpy as np
kfold = KFold ( n_splits = 5 )
scores = []
X = train_df_2 [[ 'Age_mm_sc' , 'Fare_sd_sc' , 'Family_mm_sc' , 'Pclass_le' , 'Sex_le' , 'Embarked_C' , 'Embarked_C' , 'Embarked_C' ]]
y = train_df_2 [ 'Survived' ]
for i , ( train_index , test_index ) in enumerate ( kfold . split ( X )):
X_train , X_test = X . values [ train_index ], X . values [ test_index ]
y_train , y_test = y . values [ train_index ], y . values [ test_index ]
from sklearn . linear_model import LogisticRegression
from sklearn . metrics import accuracy_score
model_lor2 = LogisticRegression ()
model_lor2 . fit ( X_train , y_train )
y_pred2 = model_lor2 . predict ( X_test )
accuracy = accuracy_score ( y_test , y_pred2 ). round ( 3 )
print ( i , '번째 교차검증 정확도는' , accuracy )
scores . append ( accuracy )
print ( '평균 정확도' , np . mean ( scores ))
enumerate : 돌면서 각각 인덱스와 값을 동시에 전달하는 반복자 // range와 다름 // 돌면서 x -train과 test 만드는 거임
2) GridSearch 적용하기 ( 하이퍼 파라미터 자동적용하기)
알고리즘 심화에서 배울 내용이지만, 미리 알려드리자면 모델을 구성하는 입력 값 중 사람이 임의적으로 바꿀 수 있는 입력 값이 있습니다. 이를 하이퍼 파라미터(Hyper Parameter) 라고 합니다. 다양한 값을 넣고 실험할 수 있기 때문에 이를 자동화해주는 Grid Search를 적용해볼 수 있습니다.
데이터 분석 프로세스 정리
MLops (Machine Learing operation) - 시니어 레벨 때