
rubus0304 님의 블로그
[머신러닝 심화 3주차] 군집 본문





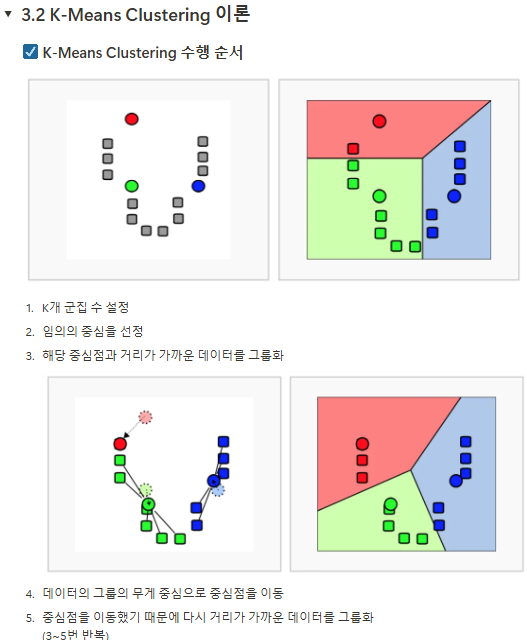

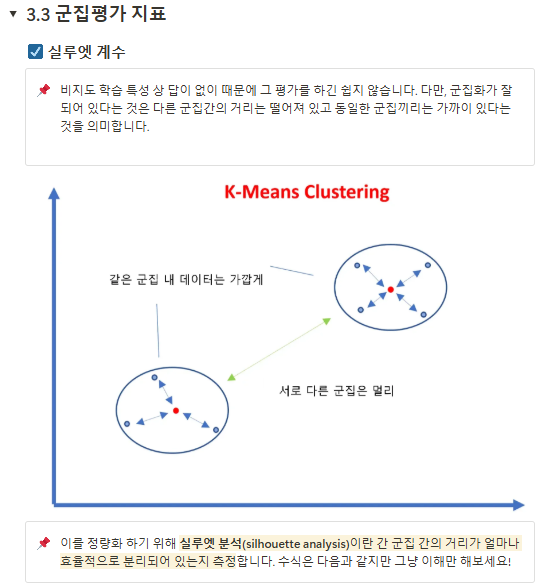
평균은 이상치에 취약.


import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
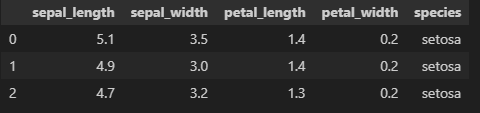
iris_df = sns.load_dataset('iris')
iris_df.head(3)
iris_df.info()
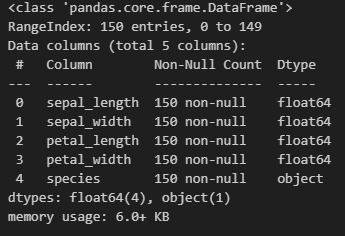
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width')
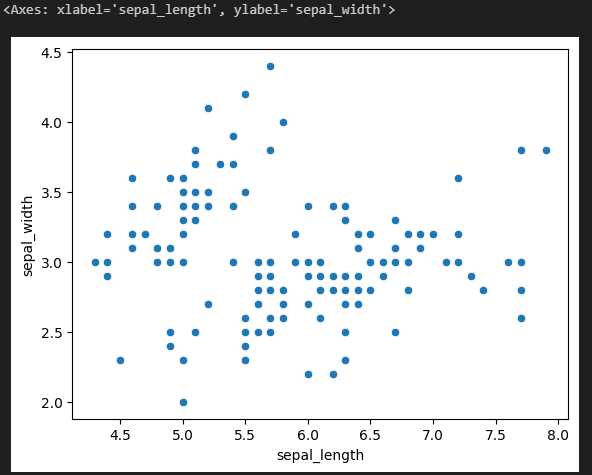
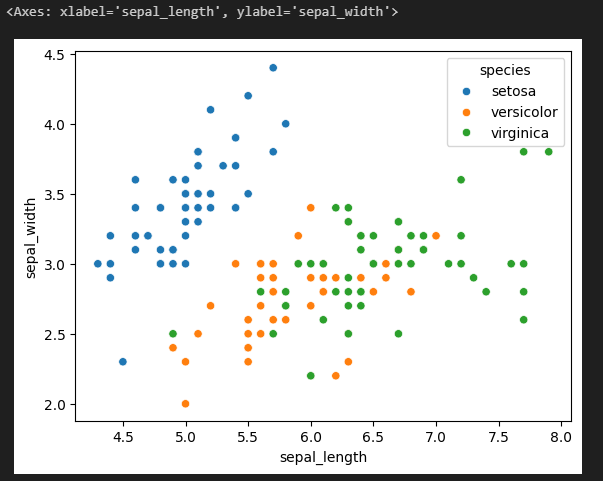
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width', hue = 'species')
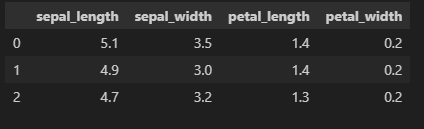
iris_df2 = iris_df[['sepal_length','sepal_width','petal_length','petal_width']]
iris_df2.head(3)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init = 'k-means++', max_iter = 300, random_state= 42)
kmeans.fit(iris_df2)

kmeans.labels_
iris_df2['target'] = iris_df['species']
iris_df2['cluster'] = kmeans.labels_
iris_df2

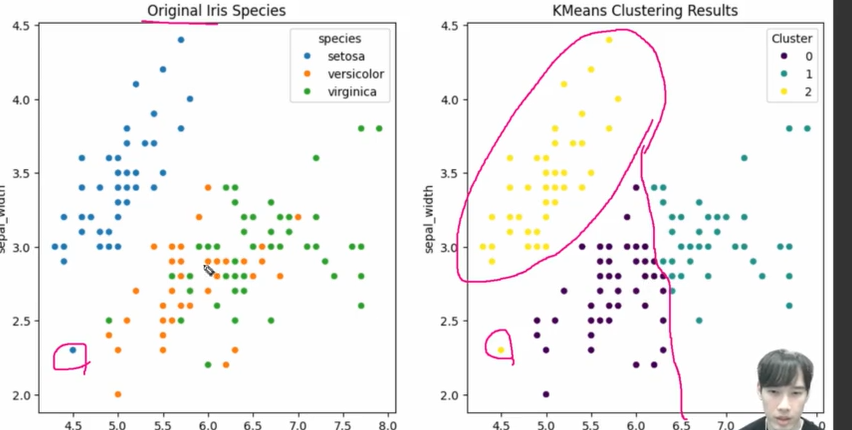
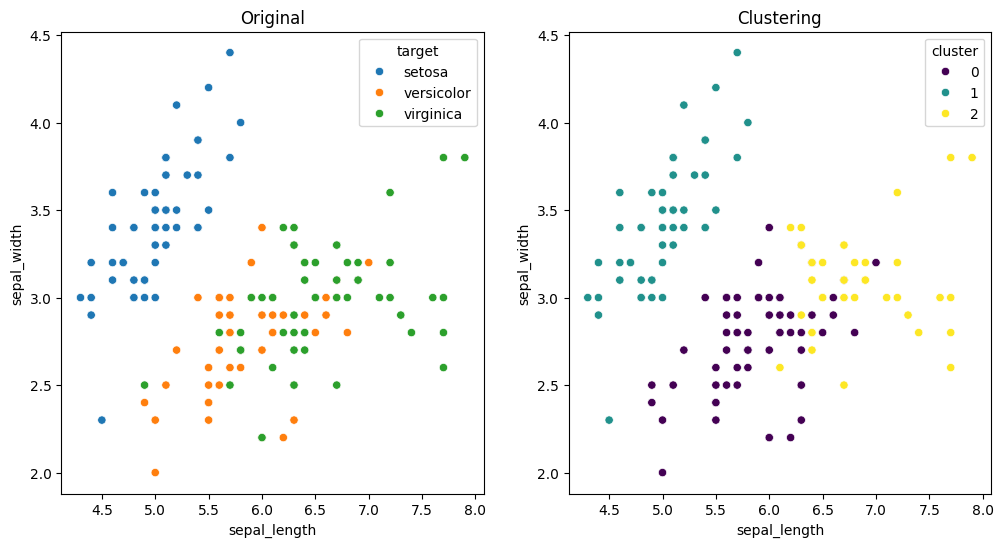
plt.figure(figsize = (12,6))
plt.subplot(1,2,1)
sns.scatterplot(data = iris_df2, x = 'sepal_length', y = 'sepal_width', hue = 'target')
plt.title('Original')
plt.subplot(1,2,2)
sns.scatterplot(data = iris_df2, x = 'sepal_length', y = 'sepal_width', hue = 'cluster', palette= 'viridis')
plt.title('Clustering')
plt.show()
(실습) 고객 세그멘테이션
☑️ 고객 세그멘테이션의 정의
비지도 학습이 가장 많이 사용되는 분야는 고객 관계 관리(Customer Relationship Management, CRM)분야 입니다.
이중 고객 세그멘테이션(Customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법입니다.
주로 타겟 마케팅이라 불리는 고객 특서엥 맞게 세분화 하여 유형에 따라 맞춤형 마게팅이나 서비스를 제공하는 것을 목표로 둡니다.
- RFM의 개념
- Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
- Frequency(F): 상품 구매 횟수
- Monetary value(M): 총 구매 금액
pip install openpyxl
xlsx 확장자 불러오기 위함.
retail_df = pd.read_excel('C:/Users/82106/Desktop/데이터분석/강의/6.파이썬/4.머신러닝/ML/Online Retail.xlsx')
retail_df.head(3)
retail_df.info()
retail_df.isnull().sum()
## 1. 데이터EDA 및 전처리
retail_df.describe(include = 'all')
cond1 = retail_df['Quantity']< 0
retail_df[cond1]
# 데이터 전처리전략
# 조건1: customerID 결측치인것은 삭제
# 조건2: Invoice가 C로 시작하거나, quantity가 음수이거나, unitprice가 음수인것은 모두 삭제
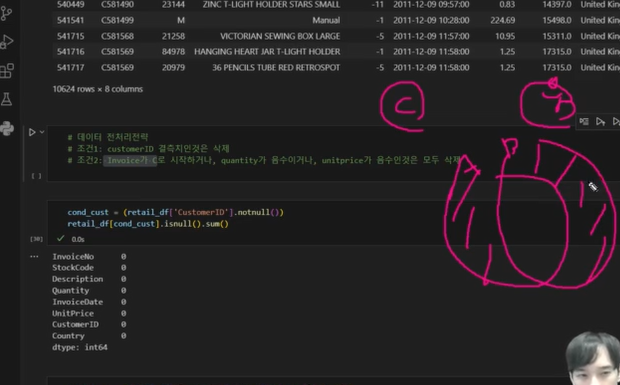
cond_cust = (retail_df['CustomerID'].notnull())
retail_df[cond_cust].isnull().sum()
cond_invo = (retail_df['InvoiceNo'].astype(str).str[0] != 'C')
retail_df[cond_invo].head(3)
cond_minus = (retail_df['Quantity'] >0 ) & (retail_df['UnitPrice'] >0)
retail_df[cond_minus].head(3)
retail_df_2 = retail_df[cond_cust & cond_invo & cond_minus]
retail_df_2.info()
retail_df_2['Country'].value_counts()[:10]
cond_uk = (retail_df_2['Country'] =='United Kingdom')
retail_df_2 = retail_df_2[cond_uk]
retail_df_2
retail_df_2.describe(include= 'all')
retail_df_2['Amt'] = retail_df_2['Quantity'] * retail_df_2['UnitPrice']
retail_df_2['Amt'] = retail_df_2['Amt'].astype('int')
retail_df_2[['CustomerID']].drop_duplicates()
retail_df_2.pivot_table(index = 'CustomerID', values = 'Amt', aggfunc='sum').sort_values('Amt', ascending=False)
import datetime as dt
# 2011.12.10일 기준으로 각 날짜를 빼고 + 1
# 추후 CustomerID 기준으로 Priod의 최소의 Priod를 구하면 그것이 Recency
# 1번사람 100일전, 20일전, 5일전
retail_df_2['Period'] = (dt.datetime(2011,12,10) - retail_df_2['InvoiceDate']).apply(lambda x: x.days+1)
retail_df_2.head(3)
rfm_df = retail_df_2.groupby('CustomerID').agg({
'Period' : 'min',
'InvoiceNo' : 'count',
'Amt' : 'sum'
})
rfm_df
rfm_df.columns = ['Recency','Frequency','Monetary']
sns.histplot(rfm_df['Recency'])
sns.histplot(rfm_df['Frequency'])
sns.histplot(rfm_df['Monetary'])
# 데이터정규화
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_features = sc.fit_transform(rfm_df[['Recency','Frequency','Monetary']])
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters = 3, random_state = 42)
labels = kmeans.fit_predict(X_features)
rfm_df['label'] = labels
silhouette_score(X_features, labels)
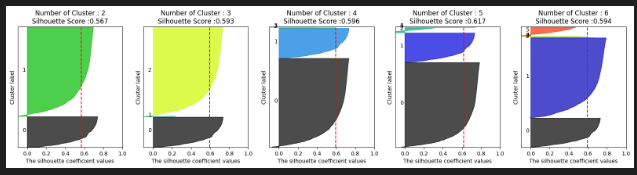
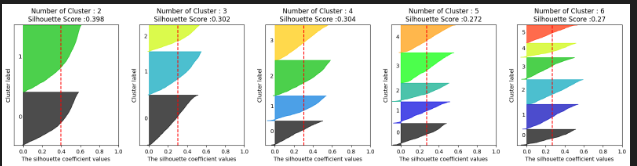
from kmeans_visaul import visualize_silhouette
visualize_silhouette([2,3,4,5,6], X_features)
#log 스케일을 통한 추가전처리
import numpy as np
rfm_df['Recency_log'] = np.log1p(rfm_df['Recency'])
rfm_df['Frequency_log'] = np.log1p(rfm_df['Frequency'])
rfm_df['Monetary_log'] = np.log1p(rfm_df['Monetary'])
X_features2 = rfm_df[['Recency_log','Frequency_log','Monetary_log']]
sc2 = StandardScaler()
X_features2_sc = sc2.fit_transform(X_features2)
visualize_silhouette([2,3,4,5,6], X_features2_sc)
'강의 > 머신러닝' 카테고리의 다른 글
| 1. 분류 프로젝트 (1) | 2024.11.28 |
|---|---|
| [머신러닝 4주차] 딥러닝 (0) | 2024.11.28 |
| [머신러닝 심화 2주차] (0) | 2024.11.27 |
| [머신러닝 심화 1주차] (0) | 2024.11.27 |
| [기초] 분류분석 - 로지스틱회귀 (1) | 2024.11.20 |
'강의/머신러닝' Related Articles
more


